The main goal of the TREC Video Retrieval Evaluation (TRECVID) is to
promote progress in content-based analysis of and retrieval from
digital video via open, metrics-based evaluation. TRECVID is a
laboratory-style evaluation that attempts to model real world
situations or significant component tasks involved in such
situations.
Then ...
Up until 2010, TRECVID used test data from a small number of known
professional sources - broadcast news organizations, TV program
producers, and surveillance systems - that imposed limits on program
style, content, production qualities, language, etc. In 2003 - 2006
TRECVID supported experiments in automatic segmentation, indexing, and
content-based retrieval of digital video using broadcast news in
English, Arabic, and Chinese. TRECVID also completed two years of
pilot studies on exploitation of unedited video rushes provided by the
BBC. In 2007 - 2009 TRECVID provided participants with cultural, news
magazine, documentary, and education programming supplied by the
Netherlands Institute for Sound and Vision. Tasks using this video
included segmentation, search, feature extraction, and copy
detection. Systems were tested in rushes video summarization using the
BBC rushes. Surveillance event detection was evaluated using airport
surveillance video provided by the UK Home Office. Many resources
created by NIST and the TRECVID community are available for continued
research on this data independent of TRECVID. See
the Past
data section of the TRECVID website for pointers.
In 2010 TRECVID confronted known-item search and semantic indexing
systems with a new set of Internet videos (referred to in what follows
as IACC) characterized by a high degree of diversity in creator,
content, style, production qualities, original collection
device/encoding, language, etc - as is common in much "Web video". The
collection also has associated keywords and descriptions provided by
the video donor. The videos are available
under Creative
Commons licenses from the Internet
Archive. The only selection criteria imposed by TRECVID beyond the
Creative Commons licensing is one of video duration - they are short
(less than 6 min). In addition to the IACC data set, NIST began
developing an Internet multimedia test collection (HAVIC) with
the Linguistic Data Consortium
and used it in growing amounts (up to 8000 h) in TRECVID
2010-present. The airport surveillance video, introduced in TRECVID
2009, has been reused each year since.
New in 2013 was video provided by the BBC. Programming from their
long-running EastEnders
series was used in the instance search task. An additional 600 h of
Internet Archive video available under Creative Commons licensing for
research (IACC.2) was used for the semantic indexing task as planned
from 2013 to 2015 with new test data each year.
In 2015 a new Video Hyperlinking task (LNK) previously run in
MediaEval was added in addition to
separating out the localization task (LOC) from semantic indexing (SIN).
Now ...
In TRECVID 2016 NIST will continue 5 of the 2015 tasks with
some revisions (INS, LOC, MED, SED, LNK), drop one (SIN), and add a new Ad-hoc Video
Search task (previously stopped after 2009).
- Video Search [IACC internet archives video data]
- Surveillance event detection [i-LIDS airport surveillance video data]
- Instance search [BBC EastEnders soap opera episodes]
- Multimedia event detection [HAVIC and YFCC100M multimedia dataset]
- Localization [IACC internet archives video data]
- Video Hyperlinking [Blip10000 dataset for Hyperlinking]
The IACC.3 dataset is approximately 4600 Internet Archive
videos (144 GB, 600 h) with Creative Commons licenses in MPEG-4/H.264
format with duration ranging from 6.5 min to 9.5 min and a mean duration
of almost 7.8 min. Most videos will have some metadata provided by the
donor available e.g., title, keywords, and description.
Data use agreements and Distribution:
Download for active participants from NIST/mirror servers. See Data use agreements
Master shot reference:
Will be available to active participants by download from the active
participant's area of the TRECVID website.
Automatic speech recognition (for English):
Will be available to active participants by download from the active
participant's area of the TRECVID website.
Three datasets (A,B,C) - totaling approximately 7300 Internet Archive
videos (144 GB, 600 h) with Creative Commons licenses in MPEG-4/H.264
format with duration ranging from 10 s to 6.4 min and a mean duration
of almost 5 min. Most videos will have some metadata provided by the
donor available e.g., title, keywords, and description.
NOTE: Be sure to reload the relevant collection.xml
files (A, B, C) in the master shot reference and remove files with a
"use" attribute set to "dropped" - these are no longer available under
a Creative Commons license and are not part of the test
collection.
Data use agreements and Distribution:
Download for active participants from NIST/mirror servers. See Data use agreements
Master shot reference:
Will be available to active participants by download from the active
participant's area of the TRECVID website.
Master I-Frames for Localization: Will be extracted by NIST
using ffmpeg for all choosen testing videos in the IACC.2.A, IACC.2.B
and IACC.2.C collections and made available to active participants by
download from the active participant's area of the TRECVID website sometime
before run submissions.
Automatic speech recognition (for English):
Available by download from the TRECVID Past Data page
Three datasets (A,B,C) - totaling approximately 8000 Internet Archive
videos (160 GB, 600 h) with Creative Commons licenses in MPEG-4/H.264
format with duration between 10s and 3.5 min. Most videos will have
some metadata provided by the donor available e.g., title, keywords,
and description
Data use agreements and Distribution:
Available by download from the Internet
Archive. See TRECVID
Past Data page. Or download from the copy on
the Dublin
City University server, but use the collection.xml files (see
TRECVID past data page) for instructions on how to check the current
availability of each file.
Master shot reference:
Available by download from the TRECVID Past Data page
Automatic speech recognition (for English):
Available by download from the TRECVID Past Data page
Approximately 3200 Internet Archive videos (50 GB, 200 h) with
Creative Commons licenses in MPEG-4/H.264 format with durations
between 3.6 and 4.1 min Most videos will have some metadata
provided by the donor available e.g., title, keywords, and description
Data use agreements and Distribution:
Available by download from the Internet
Archive. See TRECVID
Past Data page. Or download from the copy (see tv2010 directory) on
the Dublin
City University server, but use the collection.xml files (see
TRECVID past data page) for instructions on how to check the current
availability of each file.
Master shot reference:
Available by download from the TRECVID Past Data page
Common feature annotation:
Available by download from the TRECVID Past Data page
Automatic speech recognition (for English):
Available by download from the TRECVID Past Data page
The data consist of about 150 h of airport surveillance video data
(courtesy of the UK Home Office). The Linguistic Data Consortium has
provided event annotations for the entire corpus. The corpus was
divided into development and evaluation subsets. Annotations for 2008
development and test sets are available.
Data use agreements and Distribution:
-
Gatwick development data (2008 DevSet and 2008 EvalSet) by download
from password-protected servers at NIST and mirror
sites. See Data
use agreements
-
2009 i-LIDS test data from United Kingdom's Centre for Applied Science
and Technology (CAST) can be downloaded from NIST but only after CAST
has received the required information and issued a
userid/password. See here
for details.
Development data annotations:
available by download.
Approximately 244 video files (totally 300 GB, 464 h) with
associated metadata, each containing a week's worth of BBC EastEnders
programs in MPEG-4/H.264 format.
Data use agreements and Distribution: Download and fill out the
data permission agreement from the active participants' area of the
TRECVID website. After the agreement has been processed by NIST and
the BBC, the applicant will be contacted by Dublin City University
with instructions on how to download from their servers.
See Data
use agreements
Master shot reference: Will be available to active
participants by download from the TRECVID
2016 active
participant's area.
Automatic speech recognition (for English): Will be available
to active participants by download from Dublin City University.
The complete data set will be made available in one package by the task organisers.
Here are example files for system development:
- example development anchors
- example ground-truth for the development anchors
Here is the set of test anchors.
Data use agreements and Distribution:
Video and ASR will be available from a server at University of Twente
in the Netherlands. Please download the appropriate permission forms
from the
active
participant's area and follow the instructions at the top of each
form to receive the download information.
The Yahoo Flickr Creative Commons 100M dataset (YFCC100M) is a large collection of images and video
available on Yahoo! Flickr. All photos and videos listed in the collection are licensed under one of
the Creative Commons copyright licenses.
The YFCC100M dataset is comprised of:
* 99.3 million images
* 0.7 million videos
Data use agreements and Distribution:
The YFCC100M dataset can be obtained directly from Yahoo! from this link.
HAVIC is a large collection of Internet multimedia constructed by the Linguistic Data Consortium
and NIST. Participants will receive training corpora, event training resources, and two development test collections.
Participants will also receive an evaluation collection; either of:
- ~ 8,000 hour MED14 search collection (used for the evaluation) or
- ~ 1,300 hour MED14 search subset for participants with limited computing resources (used for the evaluation)
Data use agreements and Distribution:
Data licensing and
distribution will be handled by the Linguistic Data
Consortium. The MED'16
website is up and operational. Currently, only the data
license agreement will be on the site. All teams (even
pastparticipants) must submit a license agreement to the LDC.
In order to be eligible to receive the data, you must have have
applied for participation in TRECVID. Your application will be
acknowledged by NIST with a team ID, and active participant's
password, and information about how to obtain the data.
-
If you will be using i-LIDS (2009) HAVIC data, or BBC for
Hyperlinking, NIST will NOT be handling the data use agreements. See
the "Data Use Agreements and Distribution" section
for i-LIDS,
HAVIC, or BBC for Hyperlinking.
-
If you will be using IACC.1 video, the data use agreements are
available from the "Past data" webpage. You will be downloading the
data from the Dublin City University server (see above) or the
Internet Archive. See the "Data Use Agreements and Distribution"
section for IACC.1
-
If you will be needing to get a copy of Gatwick(2008), IACC.2, IACC.3, or BBC
EastEnders data you will need to complete the relevant permission
forms (from the
active
participant's area) and email the scanned page images for each
form as one Adobe Acrobat pdf of the document
to Angela Ellis.
Note that all of the IACC.2 and EastEnders data was made available
last year. So if you signed the permission form last year and do not
need to replace your original copy then you do not need to submit
another permission form this year.
In your email include the following:
As Subject: "TRECVID data request"
In the body: your name
your short team ID (given when you applied to participate)
the kinds of data you will be using - one or more of the following:
Gatwick (2008), IACC.2, IACC.3, and/or BBC EastEnders
You will receive instructions on how to download the data.
Please ask only for the test data (and optional development data)
required for the task(s) you apply to participate in and intend to
complete.
Requests are handled in the order they are received. Please allow 5
business days for NIST to respond to your request.for Gatwick or
IACC data with the access codes you need to download the data using
the information about data servers in the
the active
participant's area. Requests for the EastEnders data are forwarded
within 5 business days to the BBC and from there to DCU, who will
contact you with the download information. This process may take up to
3 weeks.
The previous Semantic Indexing task (run from 2010-2015) addressed
the problem of automatic assignment of predefined semantic tags representing
visual or multimodal concepts to video segments. In 2016 a new Ad-hoc search
task will start to model the end user search use-case, who is looking for
segments of video containing persons,objects,activities,locations, etc. and
combinations of the former.
In 2016 the task will again support experiments in the no annotation condition.
The idea is to promote the development of methods that permit the indexing of concepts
in video shots using only data from the Web or archives without the need of additional annotations.
The training data could for instance consist of images or videos retrieved by a general purpose search engine
(e.g. Google) using only the query definition with only automatic processing of the returned results.
This will not be implemented as a new variant of the task but by using additional categories for the training
types besides the A to D ones (see below). By "no annotation", we mean here that no annotation should be
manually done on the retrieved samples (either images or videos). Any annotation done by somebody else prior
to the general search does not count. Methods developed in this context could be used for building indexing
tools for any concept starting only from a simple query defined for it.
System task:
Given the test collection (IACC.3), master shot reference, and
set of Ad-hoc queries (approx. 30 queries) released by NIST, return for each query a list
of at most 1000 shot IDs from the test collection ranked according to their likelihood of
containing the target query.
Data:
The current test data set (IACC.3)
is 4593 Internet Archive videos (144GB, 600 total hours) using videos with
durations between 6.5min and 9.5min.
The development data set combines the development and test data sets of the:
Examples of previous Ad-hoc queries (used in 2008) can be found here.
Collaborative annotation:
The results of past collaborative
annotations on Sound and Vision as well as Internet Archive videos
from 2007-2013 are available for use in system development. No new
community annotation effort is planned in conjunction with TRECVID
2016.
Sharing of components:
The common organization, exchange formats and associated tools
developed within the IRIM consortium for the joint participation of
its members will be proposed for the sharing of elements among the
interested TRECVID Ad-hoc participants. More information will be made
available on a dedicated
wiki, which will be
accessible using the TRECVID 2016 active participant's userid/password
Participation types:
There will be 3 types of participation:
- Participation by submitting only automatic runs for TRECVID evaluation
- Participation by submitting only automatic runs for TRECVID evaluation
and by using an interactive system during the next VBS (Video Browser Showdown)
- Participation by using only interactive system during the next VBS (Video Browser Showdown)
Important for VBS participants:
The same data IACC.3 will be used by VBS participants. While VBS supports two kind of tasks: Known-item search and Ad-hoc search, participation in
any of the two tasks is optional and teams may choose to join both tasks. Interactive systems at VBS joining the Ad-hoc task will be tested real-time on
10 random selected queries (subset from the 30 selected for TRECVID 2016).
For questions about participation in the next VBS please contact the VBS organizers: Werner Bailer,
Cathal Gurrin, or Klaus Schoeffmann.
Training types:
Submissions:
Two main submission types will be accepted:
- Fully automatic runs (no human input in the loop): System takes a query as input
and produced result without any human intervention.
- Manually-assisted runs: where a human can formulate the initial query
based on topic and query interface, not on knowledge of collection or search results. Then
system takes the formulated query as input and produces result without further human intervention.
Each team may submit a maximum of 4 prioritized runs, per submission type, with 2
additional if they are of the "no annotation" training type and the
others are not. The submission formats are described below.
Please note: Only submissions which are valid when checked against
the supplied DTDs will be accepted. You must check your
submission before submitting it. NIST reserves the right to reject any
submission which does not parse correctly against the provided
DTD(s). Various checkers exist, e.g.,
Xerces-J: java sax.SAXCount -v YourSubmision.xml.
- Participants in the main version of the task against IACC.3
will submit real results in each run for all and only the 30 Ad-hoc queries
released by NIST and for each query at most 1000 shot IDs.
- Here for download (right click and choose "display page source" to see
the entire files) is a
DTD for Adhoc search results of one main run,
the container for one run, and a
small example of what a site would send to NIST for
evaluation. Please check all your submissions to see that they are well-formed.
- Please submit each of your runs in a separate file, named to
make clear which team has produced it. EACH file you submit
should begin, as in the example submission, with the DOCTYPE statement:
<!DOCTYPE videoAdhocSearchResults SYSTEM "http://www-nlpir.nist.gov/projects/tv2016/dtds/videoAdhocSearchResults.dtd">
that refers to the DTD at NIST via a URL and with a
videoAdhocSearchResults element even though there is only
one run included. Each submitted file must be compressed using just
one of the following: gzip, tar, zip, or bzip2.
- Remember to use the correct shot IDs in your submissions - the
ones from video segment elements the mp7 files in the master shot
reference with the format shotFILENUMBER_SHOTNUMBER. Do not use the
ID associated with the video (TRECVID2016_FILENUMBER) or the one
associated with a keyframe (shotFILENUMBER_SHOTNUMBER_RKF).
- Submissions will be transmitted to NIST via a password-protected webpage
Evaluation:
All queries (approx. 30) will be evaluated by assessors at NIST after pooling and sampling.
Please note that NIST uses a number
of rules in manual assessment of system output.
Measures:
- Mean extended inferred average precision (mean xinfAP),
which allows sampling density to vary e.g. so that it can be 100% in
the top strata, which are most important for average precision.
- As in past years, other detailed measures based on recall,
precision will be provided by the sample_eval software.
- Speed will also be measured: clock time per query search, reported in seconds (to one
decimal place).
Issues:
Detecting human behaviors efficiently in vast amounts surveillance
video is fundamental technology for a variety of higher-level
applications of critical importance to public safety and security.
The use case addressed by this task is the retrospective exploration
of surveillance video archives optionally using a system designed to
support the optimal division of labor between a human user and the
software - an interactive system.
System task:
Retrospective Event Detection: The task is to detect observations
of events based on the event definition. Systems may process the full corpus
using multiple passes prior to outputting a list of putative events observations.
The primary condition for this task will be single-camera input (i.e., the camera
views are processed independently). Multiple-camera input may optionally be run
as an additional contrastive condition.
- A SED event is defined to be "an observable action or change of state in a video
stream that would be important for airport security management". Events may vary greatly
in duration, from 2 frames to longer duration events that can exceed the bounds of the excerpt.
- 2016 systems should output detection results for any three events in the following list:
PersonRuns, CellToEar, ObjectPut, PeopleMeet, PeopleSplitUp, Embrace, and Pointing.
- The main evaluation (EVAL16) is expected to be implemented using 11 hour subset of the
multi-camera airport surveillance domain evaluation data collected by the Home Office Scientific
Development Branch (HOSDB). The Group Dynamic Subset introduced in 2015, will be rerun as SUB16,
and contain 2 hours of video limited to the Embrace, PeopleMeet and PeopleSplitUp events.
Data:
The test data will be the same i-LIDS data that
was made available to participants for previous SED evaluations.
The selected data subset for the evaluation will be extended from the EVAL15 task.
Submissions:
Submissions will follow the same format and procedure as in the SED 2015 task.
The number of submissions allowed will be defined in the Evaluation Plan.
Evaluation:
The updated
SED 2016 webpage with a link to the detailed evaluation plan will soon be available
with additional details.
It is assumed the user(s) are system experts and no attempt will be
made to separate the contribution of the user and the system. The
results for each system+user will be evaluated by NIST as to
effectiveness - using standard search measures (e.g., probability of
missed detection/false alarm, precision, recall, average precision)-
self-reported speed, and user satisfaction (for interactive runs).
Issues:
An important need in many situations involving video collections
(archive video search/reuse, personal video organization/search,
surveillance, law enforcement, protection of brand/logo use) is to
find more video segments of a certain specific person, object,
or place, given a visual example. For the past six years (2010-2015) the
instance search task has tested systems on retrieving specific instances
of objects, persons and locations. New query type will be tested this year
by asking systems to retrieve specific persons in specific locations.
In 2016 NIST will create about 30 topics, of which the first 20 will be
used for interactive systems. The task will again use the
EastEnders data, prepared with major help from several participants in
the AXES project (Access to
Audiovisual Archives), a four-year FP7 framework research project to
develop tools that provide various types of users with new and
engaging ways to interact with audiovisual libraries.
System task:
Given a collection of test videos, a master shot reference, a
set of known location/scene example videos, and a collection of
topics (queries) that delimit a person in some example videos,
locate for each topic up to the 1000 shots most likely to contain a
recognizable instance of the person in one of the known locations.
Interactive runs are welcome and will likely return many fewer
than 1000 shots. The development of fast AND effective search methods
is encouraged.
Data:
Development data: A very small sample (File ID=0) of the BBC
Eastenders test data will be available from Dublin City University. No
actual development data will be supplied. File 0 is therefore NOT
part of the test data and no shots from File 0 should be
part of any submission.
Test data: The test data for 2016 will be BBC EastEnders video in
MPEG-4 format. The example images in the topics will be in bmp
format. See above for information on how to get a copy of the test data.
Topics: Each topic will consist of a set of 4 example frame images
(bmp) drawn from test videos containing the person of interest in
a variety of different appearances to the extent possible in addition to
the name of one location. Example images/videos for the set of master locations
will be given to participants as well.
For each frame image there will be a binary mask of the region of
interest (ROI), as bounded by a single polygon and the ID from the
master shot reference of the shot from which the image example was
taken. In creating the masks (in place of a real searcher), we will
assume the searcher wants to keep the process simple. So, the ROI
may contain non-target pixels, e.g., non-target regions visible through
the target or occluding regions.
The shots from which example images are drawn for a given topic,
will be filtered by NIST from system submissions for that topic
before evaluation.
Here is an example of a
set of topics and here is
a pointer to the DTD for an instance
search topic (you may need to right click on "view source".
We will allow teams to submit multiple runs (to be counted only as
one against the maximum allowed) as long as those runs differ only in
what set of examples for a topic are used. The sets will be
defined as follows (in the DTD):
- A - one or more provided images - no video
- E - video examples (+ optionally image examples)
Auxiliary data: Participants are allowed to use various publicly
available EastEnders resources as long as they carefully note the use
of each such resource by name in their workshop notebook papers. They
are strongly encouraged to share information about the existence
of such resources with other participants via the tv16.list as
soon as they discover them.
Submissions:
Each team may submit a maximum of 4 prioritized runs (note the example
set exception mentioned above allowing up to 8 runs in one specific
case). All runs will be evaluated but not all may be included in the
pools for judgment. Submissions will be identified as either fully
automatic or interactive. Interactive runs will be limited to
5 elapsed minutes per search and 1 user per system run.
Please note: Only submissions which are valid when checked against the
supplied DTDs will be accepted. You must check your submission
before submitting it. NIST reserves the right to reject any submission
which does not parse correctly against the provided DTD(s). Various
checkers exist,
e.g., Xerces-J: java
sax.SAXCount -v YourSubmision.xml.
Here for download (though they may not display properly) is
the
DTD for search results of one run, the
container for one run, and
a
small example of what a site would send to NIST for
evaluation. Please check your submission to see that it is well-formed
Please submit each run in a separate file, named to make clear which
team it is from. EACH file you submit should begin, as in the example
submission, with the DOCTYPE statement and a
videoSearchResults element even if only one run is included.
Submissions will be transmitted to NIST via
a password-protected webpage.
Evaluation:
This task will be treated as a form of search and will accordingly be
evaluated with average precision for each topic in each run and
per-run mean average precision over all topics. Speed will also be
measured: clock time per topic search, reported in seconds (to one
decimal place).
Issues:
- Reducing the number of interactive topics [RESOLVED]
- Reducing the interactive search time [RESOLVED]
- limit interactive run users to 1 user per system [RESOLVED]
Video is becoming a new means of documenting everything from
recipes to how to change a tire of a car. Ever expanding multimedia
video content necessitates development of new technologies for
retrieving relevant videos based solely on the audio and visual
content of the video. Participating MED teams will create a system
that quickly finds events in a large collection of search videos.
System task:
Given an evaluation collection of videos (files) and a set of event
kits, provide a rank and confidence score for each evaluation video as
to whether the video contains the event. Both the Pre-Specified and
AdHoc Event tasks will be supported.
Data:
NIST will create up to 10 new AdHoc event kits. The development data
will be the same as last year. The evaluation search collection
will be the HAVIC Progress data from MED '15, with the addition of a
to be determined subset of videos from the YFCC100M data
Submissions:
Submissions will follow the MED '15 paradigm of submissions being made
as a single tarball bundle and minimal hardware/runtime reporting.
Each team can submit up to 5 Pre-Specified Event runs and up to 2
AdHoc event runs. Each run must contain results for a given condition.
Evaluation:
For Ad-Hoc each event, the submissions will be pooled across all runs
and a sample judged by human assessors at NIST. Mean inferred average
precision will be used to measure run-level effectiveness. Details
on the evaluation will be posted
on this
website.
Open issues
The localization task will challenge systems to make their concept
detection more precise in time and space. Currently video search tasks are accurate
to the level of the shot. In the localization task, systems will be asked
to determine the presence of the concept temporally within the shot,
i.e., with respect to a subset of the frames comprised by the shot,
and, spatially, for each such frame that contains the concept, to a
bounding rectangle.
A new set of 10 concepts are being tested this year where some
action concepts have been considered for evaluation.
Systems task:
For each concept from the list of 10 designated for localization,
NIST will distribute, about 5 weeks before the localization
submissions are due at NIST for evaluation, a list of shots (~1000 videos)
to be localized. Each video may or may not
contain the concept.
For each I-Frame within each shot in the list that contains the target,
return the x,y coordinates of the upper left and lower right vertices of
a bounding rectangle which contains all of the target concept and as
little more as possible. Systems may find more than one instance of a
concept per I-Frame and then may include more than one bounding box for
that I-Frame, but only one will be used in the judging since the ground
truth will contain only 1 per judged I-Frame, one chosen by the NIST
assessor that is the most prominent (e.g., largest, clearest, most central,
etc.). Assessors are asked to stick with this choice if a group of targets
are repeated over multiple frames unless the prominence changes and they
have to change their choice.
Data:
The current test data set (IACC.2.A-C) is a collection
of about 600 h and has been used between 2013-2015 in the Semantic Indexing task (SIN).
Therefore participating systems are not allowed to use
the IACC.2(A-C) annotations in their localization systems training by any means.
The development data comprises the IACC.1.A-C data sets.
However note that these collections only contains shot-level annotations (not bounding box ground truth data).
Concepts:
Submissions:
Participants in the localization task will submit in one file
per run (up to maximum 4 runs allowed), the localization data for
all and only the concept-containing I-Frames in the list of shots
distributed by NIST. A standard set of I-Frames, grouped by each master
shot and test video file, will be extracted by NIST using ffmpeg and
made available to participants.
Each line of submitted localization data will contain the following in
groups of ASCII characters separated by 1 space. X and Y coordinates
refer to the bounding rectangle. Assume the UpperLeft point in each
frame image has coordinates (0,0), LowerRightX > UpperLeftX,
LowerRightY > UpperLeftY.
Submissions will be transmitted to NIST via a
password-protected webpage
Evaluation:
Measures: Temporal and spatial localization will be
evaluated using precision and recall based on the judged items at two
levels - the frame and the pixel, respectively. NIST will then
calculate an average for each of these values for each concept and for
each run.
For each shot that is judged to contain a concept and
in the distributed list of shots, a subset of the shot's I-Frames will
be viewed and annotated to locate the pixels representing the concept.
The set of annotated I-Frames will then be used to evaluate the localization
for the I-Frames submitted by the systems.
Issues:
- Include more action concepts [RESOLVED]
Professional and user generated multimedia content is stored in abundance by broadcasting companies and internet sharing platforms.
The traditional way to provide access to these collections is via query-based search. However, in order to fully appreciate the content
available to them in large archives, users need explorative ways to access content. The concept of Video Hyperlinking is proposed as a
technology to enable this type of explorative access. In the longer term it might form the basis of a visual web that allows users to browse
information in videos in the same manner as they do now in the textual web, jumping from one video to another.
The goal in video hyperlinking is to suggest relevant to related target video segments based on the multimodal contents of the anchor
video segment. A hyperlink originates from a video segment that a user is currently watching. We call this starting segment an anchor, which
is defined by a start and an end time within a video.
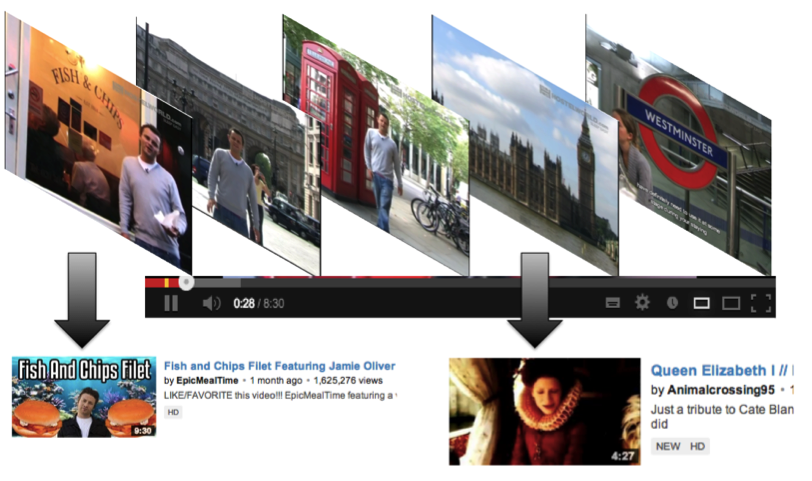
Here is an example picture giving an impression of video hyperlinking in a video segment on tourism in London: an item
on a Fish & Chips restaurant could be linked to a cooking program describing a recipe for Fish & Chips, an item on the London Parliament
could be linked to segments about England's Queen.
Relevance of a link target can be based upon topical information, the events or activities depicted, the people present in the videos, etc.
However, finding similar target video segments given an anchor video segments is not the aim in video hyperlinking.
Use scenario:
Video Hyperlinking task in 2016 investigates videomaker verbal-visual information in semi-professional user generated content (SPUG), which is commonly found on the Web.
We introduce the notion of "verbal-visual information" in order to focus the task on two aspects:
- Multimodality: The videomaker's use of a combination of the audio and visual channels to communicate the information.
- Uploader Intent: The intent of the videomaker of the video to communicate information to the viewers. The focus on intent moves us away from information that is communicated incidentally by the video.
Definition of Verbal-Visual Information: Sometimes people communicate information verbally, using spoken language. Sometimes they communicate
information visually, by showing something. However, sometimes information is communicated by a combination of speaking and showing. "Verbal-visual information"
is defined as information whose communication depends on the exploitation of both the audio and video channels of the video. If someone only listens to the video some
the information will not be fully communicated; conversely, if someone only watches the video, the information will not be fully communicated. To communicate verbal-visual
information both modalities are critically necessary.
Definition of Videomaker: A "videomaker" is a user who creates video, also sometimes called the creator or the uploader. A videomaker is a
semi-professional user if s/he has the goal to communicate a certain message to the audience, and is making use of conventional video production/editing
techniques to do it. The videomaker does not necessarily make a living from creating video, and the content might also be less polished than professional content.
Definition of Intent: "Intent" is defined to be the goal or the purpose with which someone undertakes something. In this case, we are interested
in the goal the videomaker was trying to achieve by creating the video. The motivation for considering videomaker intent to be important derives from the
investigation of uploader intent on YouTube that as carried out in [Kofler2015]. Among the intent classes identified by the study are: "Convey knowledge", "teach
practice", and "illustrate", which are all related to explanation, e.g., the communication of information. In [Kofler2015], some initial evidence for a symmetry
between the intent of users uploading video and the intent of users searching for video is uncovered. The implication is that any research progress we can make towards
techniques oriented towards uploader intent, will also directly benefit users who are searching for video.
Anchor Definition process: A person who knew the video collection well queried the collection for the linguistic cues, and then checked all the
resulting videos by the keyframe. We attempted to keep a balance in the number of anchors that showed something happening with software on a computer screen.
If there was a video which had exactly the same kind of uploader intent as had been used before we also skipped it. Otherwise, we made an anchor for every viable
video where we felt that we could identify something that was meant to be shown and for which the visual and the spoken channel both contributed to communicating
the information. We tried to make sure that the description of the anchor was concretely connected to its audio-visual content. However, if this connection was too
literal there was a chance that no target segments would be found in the collection. The anchor selectors worked on getting the appropriate balance: but it was indeed
a judgment call. Many of the anchors are going to be very challenging, but we hope that they are still interesting and will move the task into a new area.
Task:
Given a collection of videos with rich metadata and a set of anchor video segments, defined by a video ID and start time and end time, return a ranked list
of potentially relevant target video segments, defined by a video ID and start time and end time.
Approaches for video hyperlinking typically operate in two steps [Ordelman2015b]: 1) anchor representation, which select a set of important features from an anchor,
and 2) target search, which searches for the occurrence of these features in other video segments of the collection. For example, in the anchor representation step,
a system might select the word sequence "fish and chips", or the appearance of the visual concept "red telephone booth" as important features of the anchor (the former
could be found using named entity extraction and the later could be found by a corresponding visual concept detector). In the target search step, the system then searches
for segments with occurrences of these features in the collection.
We would like to make the following remarks about this general approach: Current approaches often use one modality for search ("fish and chips" is searched in spoken
content and "red telephone booth" is searched in visual content). In 2016, we encourage multimodal approaches for hyperlinking, e.g. searching for the mentioning and/or visual
appearances of fish and chips, or the mentioning of red telephone booths and/or their appearance, as this is how the anchors were selected and defined. Similarity in important
features is often a clue for the relevance of a link target. Note, however, that highly similar, especially (near-) duplicate, segments are likely to be non-relevant as they are
of no utility in the considered use scenarios.
Data:
IMPORTANT CHANGE: Withdrawal of BBC data set.
Due to issues around Data Protection and Programme Rights, BBC Research & Development regrets to announce that
it will not be able to supply data to the TRECVID evaluation this year. BBC R&D is keen to find a way to way to resolve these issues. They aim to spend the next year
establishing a dataset that can be supplied for future evaluations. However it will not be possible to do this in time for the 2016 evaluation. BBC apologises for the late
notice of this and the inconvenience it will cause.
In the context of this late notice, we decided to switch to the Blip10000 data set which consists of 14,838 videos for a total
of 3,288 hours from blip.tv. The videos cover a broad range of topics and styles. It has automatic speech recognition transcripts
provided by LIMSI; user-contributed metadata and shot boundaries provided by TU Berlin. Also, video concepts based on the MediaMil MED Caffe models are provided by EURECOM. The complete
data set is made available in one package by the task organisers. Of course, task participants are welcome to use (and share) other metadata that you create.
Anchors are defined by content creators such as media-researchers. Besides the video plus the start and end times of an anchor, the content creators also provide assessment details
of why they selected the anchor and what kind of targets they expect. This information will be used for assessment only and will not be provided to participants until the release of
submissions evaluation results.
Submissions:
- A team can submit up to four runs.
- The mandatory format of each item returned by a run is similar to the usual TREC format: <qid> Q0 <videoid> <startTime> <end> <rank> <score> <RUNID>where <qid>
is the ID of the anchor and time values have to be stated in X.Y format, where X.Y stands for X minutes and Y seconds since the start of the video (note that Y is not a fraction of X).
- Targets pointing to the video of the anchor should be excluded and will be disregarded during the evaluation.
- Targets for a given anchor must not overlap.
- The filename of run has to contain a classification of the approach according to several criteria (features and segmentations used etc) and give a hint of the approach taken.
- The filename, the format of the targets, and several constraints between targets (non-overlapping etc) have to be valid according to the publically available validation script
- Participants can provide up to 1000 proposed link targets.
- Runs will be submitted to a password-protected website at NIST and then forwarded by NIST to the task coordinator for evaluation.
Evaluation:
We will evaluate the relevance of the top results, as well as look into the diversity of the provided hyperlinks.
The evaluation of the submissions will follow the Authored hyperlinking use scenario:
Top ranked targets of participant submissions will be assessed using mechanical turk (MT) workers. Additionally, separate assessments will be created by target
users on a subset of the data to identify potential discrepancies of evaluation results based on MT workers. Assessment instructions from anchor creators will be displayed to both group of assessors.
The primary reported effectiveness measure will be MAiSP [Racca2015]. Additionally we will report several traditional precision oriented measures, adapted to unconstrained time segments, see [Aly2013].
References / Suggested Reading
[Aly2013] Aly, R. and Eskevich, M. and Ordelman, R.J.F. and Jones, G.J.F., Adapting binary information retrieval evaluation metrics for segment-based retrieval tasks. arXiv preprint arXiv:1312.1913, 2013
[Aly2013b] Aly, R. and Ordelman, R.J.F. and Eskevich, M. and Jones, G.J.F. and Chen, S., Linking Inside a Video Collection - What and How to Measure? LiME workshop at the 22nd International Conference on
World Wide Web Companion, IW3C2 2013, May 13-17, 2013, Rio de Janeiro, pp. 457-460.
[Jarvelin2002] Järvelin, K. and Kekäläinen, J., Cumulated gain-based evaluation of IR techniques. ACM Transactions on Information Systems (TOIS) 20.4 (2002): 422-446.
[Kofler2015] Kofler, C. and Bhattacharya, S. and Larson, M. and Chen, T. and Hanjalic, A. and Chang, S.F., Uploader Intent for Online Video: Typology, Inference, and Applications,
in IEEE Transactions on Multimedia, vol. 17, no. 8, pp. 1200-1212, Aug. 2015.
[Ordelman2015] Ordelman, R.J.F. and Aly, R. and Eskevich, M. and Huet, B. and Jones, G.J.F., Convenient discovery of archived video using audiovisual hyperlinking. (2015).
[Ordelman2015b] Ordelman, R.J.F. and Eskevich, M. and Aly, R. and Huet, B. and Jones, G.J.F., Defining and Evaluating Video Hyperlinking for Navigating Multimedia Archives.
In Proceedings of the 24th International Conference on World Wide Web Companion (pp. 727-732). International World Wide Web Conferences Steering Committee. (2015, May).
[Racca2015] Racca, D. N. and Jones, G.J.F., Evaluating Search and Hyperlinking: an example of the design, test, refine cycle for metric development. In Working Notes Proceedings
of the MediaEval 2015 Workshop, Wurzen, Germany, 2015.
[SHEval2015] https://github.com/robinaly/sh_eval
Automatic annotation of videos using natural language text descriptions has been a long-standing goal
of computer vision. The task involves understanding of many concepts such as objects, actions, scenes,
person-object relations, temporal order of events and many others. In recent years there has been major
advances in computer vision techniques which enabled researchers to start practically to work on
solving such problem. A lot of use case application scenarios can greatly benefit from such technology
such as video summarization in the form of natural language, facilitating the search and browsing of
video archives using such descriptions, describing videos to the blind, etc. In addition, learning video
interpretation and temporal relations of events in the video will likely contribute to other computer
vision tasks, such as prediction of future events from the video.
Video Dataset
A dataset of more than 30k Twitter Vine videos have been collected. Each has a total duration of about
6 sec long. In this showcase/pilot task a subset of 2000 Vine videos will be randomly selected annotated.
Each video will be annotated twice by two different annotators. In total, 4 sets of non-overlapping 500
videos will be given to 8 annotators to generate a total of 4000 text descriptions. Those 4000 text
descriptions will be split into 2 sets corresponding to the original 2000 videos.
Annotators were asked to include and combine in 1 sentence, if appropriate and available, four facets
of the video they are describing:
- Who is the video describing such as concrete objects and beings (kinds of persons, animals, things)
- What are the objects and beings doing? (generic actions, conditions/state or events)
- Where such as locale,site,place,geographic, architectural (kind of place, geographic or architectural)
- When such as time of day, season
Testing data and a readme file about submission formats can be found here
System Task
Given a set of 2000 urls of Vine videos and two sets (A and B) of text descriptions (each composed of
2000 sentences), systems are asked to work and submit results for two subtasks:
Matching and Ranking:
Return for each video URL a ranked list of the most likely text description that correspond (was
annotated) to the video from each of the sets A and B. Scoring results will be automatic against
the ground truth using mean inverted rank at which the annotated item is found or equivalent.
Description Generation:
Automatically generate for each video URL a text description (1 sentence) independently and
without taking into consideration the existence of sets A and B. Scoring results will be automatic
using the standard metrics from machine translation such as METEOR, BLEU or others.
Systems are encouraged to also take into consideration and use the four facets that annotators used as a
guideline to generate their automated descriptions.
Run Submissions
- Systems are allowed to submit up to 4 runs for each set in the Matching and Ranking subtask and 4 runs in the Description Generation subtask.
- Please use the strings ".A." and ".B." as part of your run file names to diffrentiate between set A and set B run files.
- A run should include results for all the testing video URLS (no missing video URL_ID will be allowed).
- No duplicate result pairs of "rank" AND "URL_ID" are allowed (please submit only 1 unique set of ranks per URL_ID). Please consult the readme file for more information regarding submission format.
- All automatic text descriptions should be in English.
- Please validate your run submissions for errors using the submission checkers here
- Submissions will be transmitted to NIST via a
password-protected webpage
- LNK data Licensing [RESOLVED]
-
TRECVID project leader:
-
General Coordinators:
-
Task coordinators:
-
See the guidelines section for the task of interest.
-
Email lists:
- Information and discussion for active workshop participants
-
[email protected]
-
archive open to active participants only
-
NIST will subscribe the contact listed in your application to
participate when we have received it. Additional members of active
participant teams will be subscribed by NIST if they send email to
the TRECVID Project Leader.
indicating they want to be subscribed, the
email address to use, their name, and providing the TRECVID 2016
active participant's password. Groups may combine the information
for multiple team members in one email. Please use this format
for submitting each name and email address (one name+address per line):
Pat Doe <[email protected]>
Once subscribed, you can post to this list by sending email to [email protected],
where they will be sent out to EVERYONE subscribed to the list, i.e.,
all the other active participants.
- Information and discussion on the surveillance event detection task
- Information and discussion on the multimedia event detection task.
 last updated:
last updated:
Date created:
Friday, 1-Jan-16
For further information contact [email protected]
{kind=link}