TRECVID is a laboratory-style evaluation that attempts to model real world situations or significant component tasks involved in such situations. In 2005 there were four main tasks with tests associated and participants must complete at least one of these in order to attend the workshop.
- shot boundary determination
- low-level feature extraction
- high-level feature extraction
- search (interactive, manual, and automatic)
In addition there was a pilot task which is optional. As part of putting the guidelines in final form, the details of this task and its evaluation were to be worked out by those who decide to participate in it.
- explore BBCrushes
2.1 Shot boundary detection:
Shots are fundamental units of video, useful for higher-level processing. The task is as follows: identify the shot boundaries with their location and type (cut or gradual) in the given video clip(s)
2.2 Low-level feature extraction:
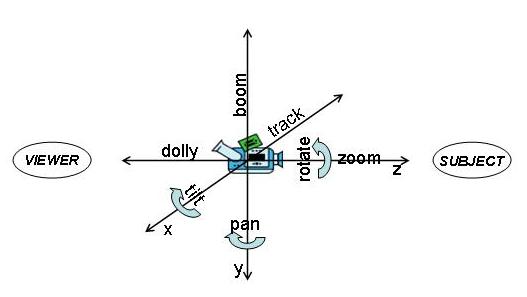
Requests for video material from archives often specify desired or required camera motion. The task was as follows: given the feature test collection, the common shot boundary reference, and the following list of 3 low-level features (feature groups), identify for each feature (group) all shots in which it is present. A feature (group) was considered present if it (one or more of its members) occurs anytime within the shot.
- pan (left or right) or track
- tilt (up or down) or boom
- zoom (in or out) or dolly
2.3 High-level feature extraction:
Various high-level semantic features, concepts such as "Indoor/Outdoor", "People", "Speech" etc., occur frequently in video databases. The proposed task was to contribute to work on a benchmark for evaluating the effectiveness of detection methods for semantic concepts
The task was as follows: given the feature test collection, the common shot boundary reference for the feature extraction test collection, and the list of feature definitions(see below), participants returned for each feature the list of at most 2000 shots from the test collection, ranked according to the highest possibility of detecting the presence of the feature. Each feature was assumed to be binary, i.e., it was either present or absent in the given reference shot.
All feature detection submissions were made available to all participants for use in the search task - unless the submitter explicitly asked NIST not to do this.
Description of high-level features to be detected:
The descriptions were meant to be clear to humans, e.g., assessors/annotators creating truth data and system developers attempting to automate feature detection. They were not meant to indicate how automatic detection should be achieved.
If the feature was true for some frame (sequence) within the shot, then it was true for the shot; and vice versa. This is a simplification adopted for the benefits it affords in pooling of results and approximating the basis for calculating recall.
NOTE: In the following, "contains x" is short for "contains x to a degree sufficient for x to be recognizable as x to a human" . This means among other things that unless explicitly stated, partial visibility or audibility may suffice.
Selection of high-level features to be detected:
We built on some interim results from the LSCOM (Large Scale Concept Ontology for Multimedia) workshop, which defined a set of 40 features which should be useful in search of news video. The following subset of 10 was then chosen for evaluation in TRECVID 2005. They represent a mixture of people, things, events, and locations. (The partial overlap with past evaluations is intentional.)
- 38. People walking/running: segment contains video of more than one person walking or running
- 39. Explosion or fire: segment contains video of an explosion or fire
- 40. Map: segment contains video of a map
- 41. US flag: segment contains video of a US flag
- 42. Building exterior: segment contains video of the exterior of a building
- 43. Waterscape/waterfront: segment contains video of a waterscape or waterfront
- 44. Mountain: segment contains video of a mountain or mountain range with slope(s) visible
- 45. Prisoner: segment contains video of a captive person, e.g., imprisoned, behind bars, in jail, in handcuffs, etc.
- 46. Sports: segment contains video of any sport in action
- 47. Car: segment contains video of an automobile
NOTE: NIST instructed the assessors during the manual evaluation of the feature task submissions as follows. The fact that a segment contains video of physical objects representing the topic target, such as photos, paintings, models, or toy versions of the topic target, should NOT be grounds for judging the feature to be true for the segment. Containing video of the target within video may be grounds for doing so.
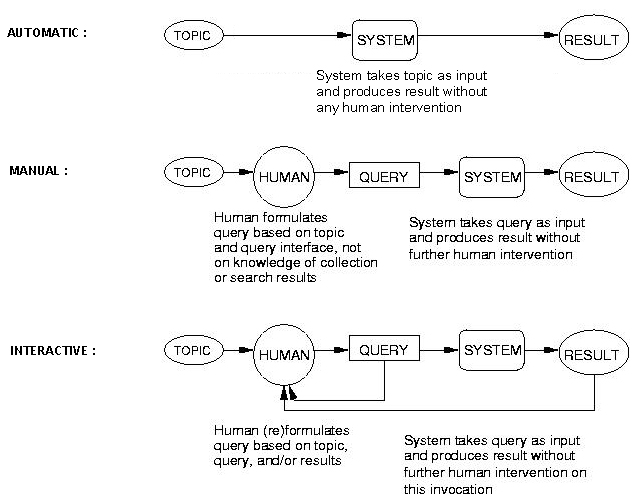
Search is high-level task which includes at least query-based retrieval and browsing. The search task models that of an intelligence analyst or analogous worker, who is looking for segments of video containing persons, objects, events, locations, etc. of interest. These persons, objects, etc may be peripheral or accidental to the original subject of the video. The task was as follows: given the search test collection, a multimedia statement of information need (topic), and the common shot boundary reference for the search test collection, return a ranked list of at most 1000 common reference shots from the test collection, which best satisfy the need. Please note the following restrictions for this task:
- TRECVID 2005 accepted fully automatic search submissions (no human input in the loop) as well as manual and interactive submissions as illustrated graphically below
- Because the choice of features and their combination for search is an open research question, no attempt was be made to restrict groups with respect to their use of features in search. However, groups making manual runs were to report their queries, query features, and feature definitions.
- Every submitted run had to contain a result set for each topic.
-
One baseline run was required of every manual or automatic system:
- A run based only on the text from the English ASR/MT output provided by NIST and on the text of the topics.
- In order to maximize comparability within and across participating groups, all manual runs within any given site had to be carried out by the same person.
- Each interactive run contained contain one result for each and every topic, each such result using the same system variant. Each result for a topic can come from only one searcher, but the same searcher does not need to be used for all topics in a run. Here are some suggestions for interactive experiments.
- The searcher should have no experience of the topics beyond the general world knowledge of an educated adult.
- The search system could not be trained, pre-configured, or otherwise tuned to the topics.
- The maximum total elapsed time limit for each topic (from the time the searcher saw the topic until the time the final result set for that topic was returned) in an interactive search run was 15 minutes. For manual runs the manual effort (topic to query translation) for any given topic will be limited to 15 minutes.
- All groups submitting search runs had to include the actual elapsed time spent as defined in the videoSearchRunResult.dtd.
- Groups carrying out interactive runs were to measure user characteristics and satisfaction as well and report this with their results, but they did not have to submit this information to NIST. Here is some information about the questionnaires the Dublin City University team used in 2004 to collect search feedback and demographics from all groups doing interactive searching. Something similar will be done again this year, with details to be determined once participation is known.
- In general, groups were reminded to use good experimental design principles. These include among other things, randomizing the order in which topics are searched for each run so as to balance learning effects.
2.5 Exploring BBC rushes:
Rushes are the raw material used to produce a video. 20 to 40 times as much material may be shot as actually becomes part of the finished product. Rushes usually have only natural sound. Actors are only sometimes present. Rushes contain many frames or sequences of frames that are highly repetitive, e.g., many takes of the same scene redone due to errors (e.g. an actor gets his lines wrong, a plane flies over, etc.), long segments in which the camera is fixed on a given scene or barely moving,etc. A significant part of the material might qualify as stock footage - reusable shots of people, objects, events, locations, etc.
The real task scenario we wanted to model is that of someone, unfamiliar with the details of an archive of rushes, who is looking for archived video segments for reuse in a new video.
The task was, given 50 hours of BBC rushes about vacation spots, a set of keyframes for each video, and minimal metadata per video, 1) build a system to help the person described above browse, search, classify, summarize, etc. the material in the archive. 2) Devise a way of evaluating such a system's effectiveness and usability.
It was hoped that enough will be learned from this exploration to allow the addition of a well-defined task with evaluation in TRECVID 2006. Participants in this task were encouraged to share information about their plans with each other and coordinate/collaborate, perhaps agreeing to narrow the scope of the exploration.
3. Video data:
A number of MPEG-1 datasets were available for use in TRECVID 2005. We describe them here and then indicate below which data will be used for development versus test for each task.Television news from November 2004
The Linguistic Data Consortium (LDC) collected the following video material and secured rights for research use. Sample development files will be available to those who have filled out and faxed in their permission forms
Language Episodes Source Program Total (hours)
======== ======= ====== ============ ==========
Arabic 15 LBC LBC NAHAR 13.13
Arabic 25 LBC LBC NEWS 23.14
Arabic 17 LBC LBC NEWS2 6.80
Chinese 28 CCTV4 DAILY_NEWS 25.80
Chinese 21 CCTV4 NEWS3 9.30
Chinese 21 NTDTV NTD NEWS12 9.28
Chinese 18 NTDTV NTD NEWS19 7.93
English 26 CNN AARON BROWN 22.80
English 17 CNN LIVE FROM 7.58
English 27 NBC NBC PHILA23 11.83
English 19 NBC NIGHTLY NEWS 8.47
English 25 MSNBC MSNBC NEWS11 11.10
English 28 MSNBC MSNBC NEWS13 12.42
-------
169.58
NASA educational science programming
Several hours of NASA's Connect and/or Destination Tomorrow series which have not yet been made public were provided by NASA and the Open Video Project. Examples were available now from the Open Video Project or NASA's ibiblio website.
BBC rushes
About 50 hours of rushes on vacation spots provided by the BBC Archive. Sample development files will be available to those who have filled out and faxed in their permission forms.
3.1 Development versus test data
A random sample of about 6 hours was removed from the television news data, combined with about 3 hours of NASA science programming, and the resulting data set used as shot boundary test data.
The remaining 160 hours of television news were split in half chronologically by source. The first halves were combined and designated as development data for the search, high/low-level feature, and shot boundary detection tasks. The second halves were combined and used as test data for the search and high/low-level feature tasks.
Half of the BBC rush video was designated as development data, the remainder as test data.
3.2 Data distribution
The shot boundary test data was express-shipped by NIST to participants on DVDs (DVD+R).
Distribution of all development data and the remaining test data was handled by LDC using loaner IDE drives, which must be returned or purchased within 3 weeks of loading it on your system unless you have gotten an exemption from LDC in advance. The only charge to participants for test data was the cost of shipping the drive(s) back to LDC. More information about the data will be provided on the TRECVID website starting in March as we know more.
Note: Participating groups from TRECVID 2005 who received a loaner drive and did not returnor buy the drive, are not eligible to participate in TRECVID 2006.
3.3 Ancillary data associated with the test data
Provided with the broadcast news test data (*.mpg) on the loaner drive were a number of other datasets.
Output of an automatic speech recognition (ASR) system
The automatic speech recognition output provided was the output of an off-the-shelf product with no tuning to the TRECVID 2005 data. Any mention of commercial products is for information only; it does not imply recommendation or endorsement by NIST.
Output of a machine translation system (X->English)
The machine translation output provided was the output of an off-the-shelf product with no tuning to the TRECVID 2005 data. Any mention of commercial products is for information only; it does not imply recommendation or endorsement by NIST.
Common shot boundary reference and keyframes:
Christian Petersohn at the Fraunhofer (Heinrich Hertz) Institute in Berlin provided the master shot reference. Please use the following reference in your papers:
C. Petersohn. "Fraunhofer HHI at TRECVID 2004: Shot Boundary Detection System", TREC Video Retrieval Evaluation Online Proceedings, TRECVID, 2004 URL: www-nlpir.nist.gov/projects/tvpubs/tvpapers04/fraunhofer.pdfThe Dublin City University team formatted the reference and creating a common set of keyframes. Our thanks to both.
To create the master list of shots, the video was segmented. The results of this pass are called subshots. Because the master shot reference is designed for use in manual assessment, a second pass over the segmentation was made to create the master shots of at least 2 seconds in length. These master shots are the ones to be used in submitting results for the feature and search tasks. In the second pass, starting at the beginning of each file, the subshots were aggregated, if necessary, until the currrent shot was at least 2 seconds in duration, at which point the aggregation began anew with the next subshot.
The keyframes were selected by going to the middle frame of the shot boundary, then parsing left and right of that frame to locate the nearest I-Frame. This then became the keyframe and was extracted. Keyframes have been provided at both the subshot (NRKF) and master shot RKF) levels.
In a small number of cases (all of them subshots) there was no I-Frame within the subshot boundaries. When this occured the middle frame was selected. (one anomally, at the end of the first video in the test collection, a subshot occurs outside a master shot.)
NOTE: You must replace the ***.mp7.xml files provided on the DVD and the loaner hard drive with those in this zip file.3.4 Common annotation of feature/search development data
We organized a cooperative effort among participating teams in which each team annotated some subset of about 40 features for the ~80 hours of development data during 4 weeks from about mid-April to late May.
The annotation was done on keyframes supplied to the annotators and this time will not be region-specific. Based on some testing of the tools done at Dublin City University, we guestimated an annotation rate of something like 1 feature-shot per sec or about 13 dedicated person-hours to annotate the ~46,000 shots in the development collection for 1 feature.
By early June all the annotations were combined and made available in MPEG-7 format, but only to teams that contributed - we wanted to encourge teams to help. This saved an individual team a huge amoung of work in the creation of training data. Also, because training data is an important factor in system performance, if we can hold it constant (see training type A ) by having many systems trained on the same data, we can better compare system performance.
Contributors choose from two tools:
- one provided by CMU for the MS Windows plattform with results collected locally
- one web-based tool from IBM with results collected centrally
Cite: Timo Volkmer, John R. Smith, Apostol (Paul) Natsev, Murray Campbell, Milind Naphade, "A web-based system for collaborative annotation of large image and video collections", In Proceedings of the 13th ACM international Conference on Multimedia, Singapore, 6-11 November, 2005
We are grateful to the Large Scale Concept Ontology for Multimedia (LSCOM) workshop group for producing the set of features to annotate. The 10 features to be evaluated for the feature extraction task will be taken from those in the common annotation effort.
3.5 Restrictions on use of development and test data
Each participating group wass responsible for adhering to the letter and spirit of these rules, the intent of which is to make the TRECVID evaluation realistic, fair and maximally informative about system effectiveness as opposed to other confounding effects on performance. Submissions, which in the judgment of the coordinators and NIST do not comply, will not be accepted.
Test data
The test data shipped by LDC cannot be used for system development and system developers should have no knowledge of it until after they have submitted their results for evaluation to NIST. Depending on the size of the team and tasks undertaken, this may mean isolating certain team members from certain information or operations, freezing system development early, etc.
Participants could use donated feature extraction output from the test collection but incorporation of such features had to be automatic so that system development was not affected by knowledge of the extracted features. Anyone doing searches had to be isolated from knowledge of that output.
Participants could not use the knowledge that the test collection came from news video recorded during November of 2004 in the development of their systems. This would have been unrealistic.
Development data
The development data was intended for the participants' use in developing their systems. It was up to the participants how the development data was used, e.g., divided into training and validation data, etc.
Other data sets created by LDC for earlier evaluations and derived from the same original videos as the test data cannot be used in developing systems for TRECVID 2005.
If participants used the output of an ASR/MT system, they had to submit at least one run using the English ASR/MT provided by NIST. They were free to use the output of other ASR/MT systems in additional runs.
Participants could use other development resources not excluded in these guidelines. Such resources should be reported at the workshop. Note that use of other resources changed the submission's status with respect to system development type, which is described next.
- A - system trained only on common TRECVID development collection
data, the common annotation of such data, and any truth data created
at NIST for earlier topics and test data, which is publicly
available. For example, common annotation of 2003 training data and
NIST's manually created truth data for 2003 and 2004 could in theory
be used to train type A systems in 2005.
Since by design we have multiple annotators for most of the common training data features but it is not at all clear how best to combine those sources of evidence, it seems advisable to allow groups using the common annotation to choose a subset and still qualify as using type A training. This may be equivalent to adding new negative judgments. However, no new positive judgments can be added.
- B - system trained only on common development collection but not on (just) common annotation of it
- C - system is not of type A or B
3.6 Data license agreements for active participants
In order to be eligible to receive the test data, you had to have applied
for participation in TRECVID, be acknowledged as an active participant, have
completed both of the following forms and faxed them (Attention: Lori Buckland)
to
 in the US.
in the US.
- Television news from November 2004
- form (return to NIST)
- BBC rushes
- organization form (return to NIST)
- individual form (retain for your records)
4. Information needs and topics:
4.1 Example types of informations needs
I'm interested in video material / information about:- a specific person
- one or more instances of a category of people
- a specific thing
- one or more instances of a category of things
- a specific event/activity
- one or more instances of a category of events/activities
- a specific location
- one or more instances of a category of locations
- combinations of the above
As an experiment, NIST may create a topic of the form "I'm looking for video that tells me the name of the person/place/thing/event in the image/video example"
Topics may target commercials as well as news content.
4.2 Topics:
The topics, formatted multimedia statements of information need, were be developed by NIST who controled their distribution. The topics expressed the need for video concerning people, things, events, locations, etc. and combinations of the former. Candidate topics (text only) were created at NIST by examining a large subset of the test collection videos without reference to the audio, looking for candidate topic targets. The goal was to create about equal numbers of topics looking for video of person, things, events, locations. Accepted topics were enhanced with non-textual examples from the Web if possible and from the development data if need be. The goal was to create 25 topics.
* Note: The identification of any commercial product or trade name does not imply endorsement or recommendation by the National Institute of Standards and Technology
- Topics describe the information need. They are input to systems and guide to humans assessing relevance of system output
- Topics are multimedia objects - subject to the nature of the need and the questioner's choice of expression
- As realistic in intent and expression as possible
- Template for topic:
- Title
- Brief textual description of the information need (this text may contain references to the examples)
- Examples* of what is wanted:
- reference to video clip
- Optional brief textual clarification of the example's relation to the need
- reference to image
- Optional brief textual clarification of the example's relation to the need
- reference to audio
- Optional brief textual clarification of the example's relation to the need
5. Submissions and Evaluations:
Please note: Only submissions which were valid when checked against the supplied DTDs were accepted. You must check your submission before submitting it. NIST reserves the right to reject any submission which does not parse correctly against the provided DTD(s). Various checkers exist, e.g., the one at Brown University, Xerces-J,, etc.
The results of the evaluation were made available to attendees at the TRECVID 2005 workshop and were published on the TRECVID website within six months after the workshop. All submissions are likewise available to interested researchers via the TRECVID website within six months of the workshop.
5.1 Shot boundary detection
- Participating groups could submit up to 10 runs. Please note required attributes to accommodate complexity information (total decide time (secs), total segmentation time(secs), and processor type) for each run was be added to the 2005 submission DTD. All runs were evaluated.
- Here is the DTD for the shot boundary detection results of one run, one for the enclosing shotBoundaryResults element and a small, partial example. Please place the output of each run in a separate file. You can tar/zip the (up to 10) run files together for submission. Remember that each run much test one variant of your system against all the test files. Please check your submission to see that it is well-formed
- Please send your submissions (up to 10 runs) in an email to over at nist.gov. Indicate somewhere (e.g., in the subject line) which group you are attached to so that we match you up with the active participant's database.
- Automatic comparison to human-annotated reference. Software for this comparison is available under Tools used by TRECVID from the main TRECVID page.
- Measures:
- All transitions: for each file, precision and recall for detection; for each run, the mean precision and recall per reference transition across all files
- Gradual transitions only: "frame-recall" and "frame precision" will be calculated for each detected gradual reference transition. Averages per detected gradual reference transition will be calculated for each file and for each submitted run. Details are available.
5.2 Low-level feature extraction
Submissions
- The maximum number of runs each participating group could submit was 7.
- Each run had to contain results for all three features (i.e., feature groups).
- For each feature in a run, participants returned all and only the shots from the master shot reference for which the feature was true.
- Here is a DTD for camera motion feature detection results of one run, one for results from multiple runs, and a small, partial example of what a site would send to NIST for evaluation. Please check your submission to see that it is well-formed
- Please send your submission in an email to NIST (overATnistDOTgov). Indicate somewhere (e.g., in the subject line) which group you are attached to so that we match you up with the active participant's database. Send all of your runs as one file or send each run as a file but please do not break up your submission any more than that. A run will contain results for all features you worked on.
Evaluation
- Because the low-level camera movement
features are very frequent and often (especially in combination) very
difficult even for a human to detect, the low-level feature task was
evaluated differently from the high-level feature task.
In advance of any submissions, NIST chose a random subset of the test collection and manually annotate each shot for each of the features. The number of shots was as large as our resources allowed. We allowed ourselves to drop from the annotated subset, shots for which the feature is not clearly true or false in the judgment of the annotator. For example, when a handheld camera resulted in a minor camera movement in many directions we often dropped that shot. This was partly to assure that annotations were reliable and because we did not think a user asking, for example, for a panning or tracking shot would want such shaky shots returned.
As it ended up, we had time to look at 5000 shots chosen at random from the feature/search test data. From this first pass we kept what seemed reasonably clear examples of each feature (group) as well as examples of shots with no camera motion.
In second pass we doublechecked and corrected the output of the first pass. The ground truth for each feature then consisted of the shots we found for which the feature (group) was true (Pan:587, Tilt:210, Zoom:511) plus the shots we found for which the feature was clearly not true (i.e., the "no motion" shots:1159). This is clearly not a simple random sample and we have not attempted to balance the relative size of any of the sets.
NIST evaluated each submission automatically using the truth data to produce an official set of results for the workshop. Then NIST made the truth data available to participants so they could continue to experiment with their systems and evaluate the results on their own.
- Runs were compared using precision and recall - two measures per feature run.
5.3 High-level feature extraction
Submissions
- The maximum number of runs participating groups could submit was be 7. All runs had to beprioritized and all were evaluated.
- For each feature in a run, participants could return at most 2000.
- Here is a DTD for feature extraction results of one run, one for results from multiple runs, and a small example of what a site would send to NIST for evaluation. Please check your submission to see that it is well-formed
- Please send your submission in an email to NIST (overATnistDOTgov). Indicate somewhere (e.g., in the subject line) which group you are attached to so that we match you up with the active participant's database. Send all of your runs as one file or send each run as a file but please do not break up your submission any more than that. A run will contain results for all features you worked on.
Evaluation
- The unit of testing and performance assessment was the video shot as defined by the track's common shot boundary reference. The submitted ranked shot lists for the detection of each feature were judged manually as follows. We took all shots down to some fixed depth (in ranked order) from the submissions for a given feature - using some fixed number of runs from each group in priority sequence up to the median of the number of runs submitted by any group. We then merged the resulting lists and create a list of unique shots. These were judged manually down to some depth to be determined by NIST based on available assessor time and number of correct shots found. NIST maximized the number of shots judged within practical limits. We then evaluated each submission to its full depth based on the results of assessing the merged subsets. This process was repeated for each feature.
- If the feature is perceivable by the assessor for some frame (sequence) however short or long then, then we'll assess it as true; otherwise false. We'll rely on the complex thresholds built into the human perceptual systems. Search and feature extraction applications are likely - ultimately - to face the complex judgment of a human with whatever variability is inherent in that.
- Runs will be compared using precision and recall. Precision-recall curves will be used as well as a measure which combines precision and recall: average precision(see below under Search for details).
5.4 Search
Submissions
-
Each participating group could submit up to 7 prioritized runs. All runs
had to be prioritized and all were evaluated.
Each interactive run contained one result for each and every topic using the system variant for that run. Each result for a topic could come from only one searcher, but the same searcher did not need to be used for all topics in a run. If a site had more than one searcher's result for a given topic and system variant, it was up to the site to determine which searcher's result was included in the submitted result. NIST tried to make provision for the evaluation of supplemental results, i.e., ones NOT chosen for the submission described above. Details on this were available by the time the topics are released.
- For each topic in a run, participants returned the list of at most 1000 shots. Here is a DTD for search results of one run, one for results from multiple runs, and a small example of what a site would send to NIST for evaluation. Please check your submission to see that it is well-formed
- Please send your submission in an email to overATnistDOTgov. Indicate somewhere (e.g., in the subject line) which group you are attached to so that we match you up with the active participant's database. Send all of your runs as one file or send each run as a file but please do not break up your submission any more than that. Remember, a run will contain results for all of the topics.
Evaluation
- The unit of testing and performance assessment was the video shot as defined by the track's common shot boundary reference. The submitted ranked lists of shots found relevant to a given topic were judged manually as follows. We took all shots down to some fixed depth (in ranked order) from the submissions for a given topic - using some fixed number of runs from each group in priority sequence up to the median of the number of runs submitted by any group. We then merged the resulting lists and created a list of unique shots. These were judged manually to some depth to be determined by NIST based on available assessor time and number of correct shots found. NIST maximized the number of shots judged within practical limits. We then evaluated each submission to its full depth based on the results of assessing the merged subsets. This process was repeated for each topic.
- Per-search measures:
- average precision (definition below)
- elapsed time (for all runs)
- Per-run measure:
-
mean average precision (MAP):
Non-interpolated average precision, corresponds to the area under an ideal (non-interpolated) recall/precision curve. To compute this average, a precision average for each topic is first calculated. This is done by computing the precision after every retrieved relevant shot and then averaging these precisions over the total number of retrieved relevant/correct shots in the collection for that topic/feature or the maximum allowed result set (whichever is smaller). Average precision favors highly ranked relevant documents. It allows comparison of different size result sets. Submitting the maximum number of items per result set can never lower the average precision for that submission. The topic averages are combined (averaged) across all topics in the appropriate set to create the non-interpolated mean average precision (MAP) for that set. (See the TREC-10 Proceedings appendix on common evaluation measures for more information.)
5.5 Explore BBC rushes
Given the exploratory nature of this task, there were no plans for required submissions or evaluation at NIST.
6. Milestones:
The following were the dates for 2005.
- 31. Jan
- NIST sends out Call for Participation in TRECVID 2005
- 15. Feb
- Applications for participation in TRECVID 2005 due at NIST
- 1 Mar
- Final versions of TRECVID 2004 papers due at NIST
- 12. Apr
- Guidelines complete
LDC begins shipping hard drives
Common development annotation effort begins - 25. May
- Common annotation complete
- 1. June
- Common annotation results available to annotators
- 15. Jul
- Shot boundary test collection DVDs shipped by NIST
- 12. Aug
- Search topics available from TRECVID website.
- 15. Aug
- Shot boundary detection submissions due at NIST for evaluation.
- 22. Aug
- Feature extraction tasks submissions due at NIST for evaluation.
Feature extraction donations due at NIST - 24. Aug
- Feature extraction donations available for active participants
- 27 Aug
- Results of shot boundary evaluations returned to participants
- 29. Aug - 14. Oct
- Search and feature assessment at NIST
- 20. Sep
- Results of feature extraction evaluations returned to participants
- 21. Sep
- Search task submissions due at NIST for evaluation
- 17. Oct
- Results of search evaluations returned to participants
- 23. Oct
- Speaker proposals due at NIST
- 30. Oct
- Notebook papers due at NIST
- 7. Nov
- Workshop registration closes
- 9. Nov
- Copyright forms due back at NIST (see Notebook papers for instructions)
- 14,15 Nov
- TRECVID Workshop at NIST in Gaithersburg, MD (Registration, agenda, etc)
- 18. Nov
- Workshop papers publicly available (slides added as they arrive)
- 1. Mar 2006
- Final versions of TRECVID 2005 papers due at NIST
7. Input to planning TRECVID 2006
8. Results and submissions
9. Information for active participants
10 Contacts:
- Coordinators:
- and
- NIST contact:
- Email lists:
- Information and discussion for active workshop participants
- General (annual) announcements about TRECVID (no discussion)
 Last
updated:
Last
updated: Date created: Monday, 25-Jan-05
For further information contact