We first introduce the problem domain and give an overview of the tool and its mode of operation. However, our main emphasis is to present the results of a case study which was undertaken in order to assess user reactions to the novel presentation of the manual information and thus refine our approach in developing the software.
The case study consisted of in-depth interviews with domain experts and detailed monitoring of their behavior while using the augmented manual. Our objective was to observe and record user reactions to the semantic links, the perceived relevance and usefulness of the links, and, most importantly, whether the users felt that the links enhanced their ability to perform information discovery tasks on the manual text.
The work reported on here forms part of our ongoing research into the creation of a tool to enhance information discovery and management potential for users of the SSA?s Program Operations Manual System (POMS). The POMS is a moderately large procedural manual (currently approx. 100MB, or 41,000 pages) which is consulted by Agency employees on a frequent and routine basis for a variety of information discovery and management tasks, including:
The master copy of the manual resides at SSA headquarters, and is in a continual state of revision and growth, as new laws, court rulings, policy changes and the like are manually incorporated into it by human writers and editors, as referred to above. A snapshot of this master copy is distributed monthly on CDROM to SSA field offices throughout the U.S., with each month's copy superceding that of the previous month.
The manual has a fairly strict, hierarchical document structure, with
six levels: Part, Chapter, Subchapter, Section, Subsection, and Subsubsection.
Text segments at the various levels of the hierarchy are systematically
labeled to reflect their position in the hierarchy. Table 1 gives as an
example a breakdown of the hierarchical path to Subsubsection DI 10505.010.A.3.
This hierarchy resembles that described by Frisse (1988), though the depth
of subpart dependency is not as great.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The text of the CDROM distribution is marked up in a proprietary format resembling SGML, and is designed to be used in conjunction with a browser which is included with the distribution and which incorporates a Boolean search engine. This version of the POMS is, in essence, a hypertext document, since it includes structural links (e.g. a link from a table of contents to a Section) and referential links (e.g. a link from a citation to the cited text).
In summary, the POMS consists of a large, text-based manual accessed via a fairly standard Boolean search interface. At any given time, moreover, it exists in two versions: a snapshot of the master copy on CDROM in the SSA field offices, which is stable on a monthly basis; and the master copy itself, at SSA headquarters, which is under frequent revision.
A study by Dimitroff and Wolfram (1995) testifies to the ease of use of hypertext. They conducted a usability evaluation study of a hypertext-based information retrieval system which found little or no variation in the duration of search between experienced and novice users. The researchers concluded that such systems "can be successfully searched by individuals with a wide range of experience". This was of particular interest to us, since one of our objectives was the production of a tool which is easily used and has a rapid learning curve. Baron et al. (1996) describe a study in which the efficacy of typed or labeled hypertext links in aiding information discovery was assessed against that of both unlabeled links and the absence of links. Their conclusions indicate that labeled links produced significant gains in what they term query performance (i.e. speed of information discovery), when compared to either of the other link categories. This conclusion supports that of Dimitroff and Wolfram and extends it to indicate that typed or labeled links are of most use. Our proposed design included the production of a document base with a single semantic link type. In order to maximize the utility of these links, we decided to group them together under a title describing the type of the links.
The appeal to us of IR technology lay not only in the natural language-style user interface, but also in its potential use in the automatic creation and updating of hypertext document webs. Agosti (1997), sums up a pervasive theme in the field of automatic hypertext construction: "Since the most difficult part of the automatic construction of a hypertext is building up the links that connect semantically related documents..., it is natural to concentrate on IR techniques, that have always dealt with the construction of relationships dependent on the mutual relevance of objects...". Significant efforts in the automatic linking of documents or of passages within documents (for example Agosti et al. (1996), Allan (1997), Salton et al. (1996)) have demonstrated that IR technology can readily be applied in the construction of semantic links between one body of text and another. It seemed that this approach would work well in our case, as our envisioned end product would be a fairly dynamic, internally linked document web which would be automatically recreated on a regular basis to reflect changes to the base document collection (the "master copy" referred to above). We decided that IR technology might easily be integrated into such a process, and we had a tried and tested IR search engine to hand in NIST's PRISE system (Harman and Candela, 1990).
Thus we envisioned a tool with three key components:
We hoped to use the POMS as the basis of a prototype online, dynamic, adaptive manual system.
Our objectives were fourfold:
The POMS was augmented using NIST's prototype LEIDIR software, which is designed to create a web of documents from documents or document collections of arbitrary size and format. This is achieved by inserting into each document semantic links to the n most similar documents in the collection, where n is a user-configurable value. In this study, n was set to 5: we wanted to provide a variety of target documents while maintaining a manageably-sized list of links. We refer to the inserted links as semantic links because they are intended to convey a relationship between the content or subject matter of the linked documents. According to Allan's (1997) link taxonomy, the links we employ are equivalence links, because they link documents with a similar subject matter (semantic links of other types are for future study). The resultant documents are formatted in HTML, making them accessible via any World Wide Web browser and thereby removing the need for specialized browsers to view the text.
The system is designed with the goal of providing automatic maintenance of the semantic web as necessary. At the moment this requires rebuilding the web and is thus limited to an overnight run, but with incremental indexing and refinement of software and hardware components, the web could be maintained in real time.
LEIDIR has four principal software components:
The main processor module is the heart of LEIDIR, and yet, for the time being, its operation remains relatively straightforward: each second generation document is passed to the search engine as a query over the entire second generation collection. HTML links to the top n-ranked (see above) documents are then inserted at the end of the query document, thus creating a document collection in which each document is linked to n others. The inserted links are preceded by a short text label which identifies their origin and function. Along the way, a simplistic calculation is employed to assign a Percentage Similarity Measure (PSM) to each inserted link: the idea behind this measure is to give a rough estimate of the similarity between the document containing the link and the target document of the link, thus aiding the user in making the decision as to whether to follow the link. Finally, a structural link to the search engine interface is inserted at the end of each document.
Figure 1 shows the general appearance of a completed document, with
links.
Although SSA's role in the black lung program has diminished considerably, we are still responsible for maintaining the Part B beneficiary rolls, certain new Part B survivor claims, and some appealed black lung claims which are still in the pipeline. The Department of Labor (DOL) is responsible for all Part C claims (see DI 11045.001 and DI 11045.190 ) including those which were reviewed by DOL and--or SSA under the 1977 amendments to the Federal Coal Mine Health and Safety Act.
. . .
B. Request for Reconsideration
ODO has responsibility for both the disability and nondisability aspects of Part B black lung claims. Therefore, if a claimant files a request for reconsideration and the black lung folder is not needed by the DO, forward the request for reconsideration and any evidence the claimant wishes to submit in connection with his appeal directly to ODO following the procedures used in title II disability claims. Be sure to show that the request for reconsideration pertains to a black lung claim. If the DO needs the black lung folder in connection with any inquiry or request for reconsideration, it should be requested following the same guides used in requesting title II DIB folders. Again be sure to show that the request pertains to a black lung folder.
The search engine we employed was NIST's experimental PRISE system, a statistically-based, ranking information retrieval engine. The search engine serves two vital functions: it is essential in the creation of the semantically linked document web, as described above: the ranked output from the search engine determines which semantic links will be inserted between documents; it also serves as an entry point into the document web. The user initially submits a text query to the search engine, and is returned links to a number of documents in the collection, ranked in order of relevance. Following one of these links takes the user to a document, and the user is then free to browse within the web using the semantic links included in each document.
The HTML browser is essential for viewing the document web, and the choice of browser can markedly affect the utility of the system. Such features as a search utility, a good history mechanism, bookmarking facility, and display configuration were all found to be of assistance to the users in this study.
The participants in the study were SSA staff with a minimum of three years' experience using the POMS on a daily basis. Of the six volunteers who took part, three drew mainly upon their experience as field officers, two on their experience as POMS editors and instructors, and one as a POMS writer. All were very knowledgeable about the POMS, to the degree that they could easily tell the subject area of a Section by looking at the Section number.2
Prior to this study, the principal mode of interaction with the POMS for all participants had been through the CDROM editions and the associated Boolean search engine. About half of the participants had used a modified version of this software in order to carry out editing tasks, as opposed to simple lookup.
Study Sessions
The study was split into four sessions, each of which included one or two participants. Each session began with a brief introduction to LEIDIR and the augmented POMS, and the goals of the study, which were stated thus:
The fourth element of the session lasted about an hour. The participants were asked to use the system as best they could to gather information about items or tasks they might typically attempt to find in the course of their regular work (indeed, the usual starting point for most participants was to move directly to an inquiry or subject area they were working on at the time). Participants were encouraged to describe and discuss their actions and motivations at every stage, as well as any other comments or thoughts they might have, as openly as possible. The participants acted independently during this element, the researcher restricting his actions to observations and technical assistance with the system.
The last part of each session consisted of a fourteen-part evaluation questionnaire in which participants were asked to give specific thoughts on selected aspects of the system.
The fourth and fifth elements of each session were recorded on audio tape for later analysis, with the permission of the participants. Each session yielded about one hour and ten minutes of audio tape.
On the positive side, the links were seen as enhancing navigation through the document space, enabling the user to home in on a subject area, and getting the user on track with a particular topic. A contrasting view was that the links helped widen the user's information discovery options.
The predominant view was that the presence of the links decreased the search time required to retrieve a given information item significantly, as compared to the search engine alone. Reasons cited for this included continual back-stepping to the search results screen of the search engine, and reformulation of search topics in order to browse a variety of documents. Browsing via the links was seen as an aid to steering the user in the right direction, especially in cases where there was no clear vision of what information was required.
One user felt the presence of the links made no difference in the utility of the system.
There was also support for the insertion of a structural link back to the search engine at the top of each document, as well as at the bottom (and points in between, for long documents), and for structural links to the previous and next document (in the order they occur in the POMS) at the top and bottom of each document.
The participants were asked whether they would find the links more useful if they were further typed, specifically according to the location (POMS Part) of the target document, and, further, if this type was indicated by displaying the links in different colors. None of the participants responded favorably to this suggestion, saying that the fact that the link titles showed the Section number and title of the target document was sufficient.
Suggested improvements included a better explanation of the Percentage Similarity Measure and a plea for the addition of referential links.
The second camp did not trust the figures, feeling that they had been "misled" by high PSMs into looking at target documents with very little connection with the source document, or, mysteriously, that just because a document appeared similar to the source document did not mean that it was similar. This latter view seems more a product of gut feeling than empirical experience.
The third camp was very positive about the PSMs, and indeed suggested that the value of the PSM be used as a threshold for inclusion of links, thus introducing a variable number of links per document, an idea which is under consideration for the next phase of the LEIDIR prototype.
A strenuous pitch was made for the addition of referential links, i.e. the insertion of hypertext links at existing cross-references between documents. Such references were seen as a crucial class of link between different Parts of the POMS - a class of link which could not be replaced by the semantic links installed by LEIDIR.
Overall, the introduction of semantic links into the POMS document base was well received. In particular, the links were useful when the information requirement was ill-defined, i.e. when it was necessary to browse the document collection. The links were also useful in targeting a known document within a set of documents whose subject matter was well-defined - also a browsing task.
The problems with link reliability (discussed below) also affected the perception of the PSMs, so that the participants were less willing to trust the figures.
Overall, there seemed to be some difficulty with the notion of document similarity. Participants were unsure of how two documents could be determined to be semantically similar; some believed document similarity to be a subjective concept. Coupled with the unreliability of some of the links, participants' faith in the concept was diminished..
This idea is very appealing and has obvious merits - the participants were often more concerned about what they were not seeing than with what they were. Such a formula for link insertion would go a long way to address such concerns.
The participant "wish list" of suggested improvements to the prototype interface is instructive in that the features the users most wanted to see added were precisely those features they were accustomed to using in the Boolean POMS search engine. In many instances the users clearly felt hamstrung by the absence of these features.
In return, our study was hamstrung, to a degree, by the users? reliance on familiar frames of reference and by their expertise, which was a quality we had sought but which turned out to be far greater than expected. Domain familiarity effectively nullified two of our principal areas of inquiry: link typing and the document similarity measure (PSM). Since the document numbers (POMS Section numbers) were displayed in the link titles, the participants required no additional information. Thus link typing, at least in the way we suggested, was dismissed completely, and the document similarity measure was welcomed as the basis for computing the number of links to be displayed, but not as a visual aid in the interface.
It may be that the user-related effects described here would be offset by a longer exposure time to the prototype. Our study was, in every case, very short (less than half a day). Given time, the more experienced users would have the opportunity to assimilate the workings of the prototype and the effect of domain expertise might diminish. This is an area for further study.
Since completion of the study, we have modified the PRISE software to incorporate query processing and a more effective length normalization function, Robertson et al?s BM25 function (Robertson, et al, 1995), and the problem has been eliminated.
Since this is entirely an implementation issue, it will not be treated further here except to say that, given the generally positive reaction to the links in the study, it is reasonable to suggest that, given better links, the reaction would be more positive still.
The problem is discussed in greater depth in Appendix 1 for the record.
Our results confirm that it is possible, desirable and worthwhile to use Information Retrieval-based technology to create semantic document webs from existing large-scale document collections. Further, such webs can be dynamic in nature (though our study does not directly demonstrate this) and widely accessible through the World Wide Web.
Automatically-generated semantic links installed between the documents in such a web are generally reliable and provide a valuable browsing capability, allowing users to search around a general subject area and target a specific information item, or to start from a known item and search around it to build a broader information base. However, it appears that the value of this browsing capability decreases with the domain expertise of the user. This finding complements those of Dimitroff and Wolfram (1995) and Baron et al (1996), since it relates to the expertise of the user relative to a knowledge domain, while the earlier studies evaluated the expertise of the user in terms of experience with hypertext systems.
The inclusion of automatically-generated semantic links between documents in a collection speeds the location of information, when compared with the use of a search engine alone. This is in accordance with Dimitroff and Wolfram (1995) and Baron et al (1996).
While valuable in the information discovery process, semantic links alone are insufficient as the basis of an automatically-generated hypertext: structural and referential links should also be present, especially if the document collection is specialized and/or domain experts are likely users.
Ideally, the number of links included per document should be a function of the similarity of the target documents to the source document, as opposed to some fixed quota. The links should be incorporated in such a way as to be easily accessible from the head of the source document (perhaps in a separate window), and a link back to the search or entry page should be available at all times.
Our results indicated that visual typing of links or the addition of percentage scores to indicate document similarity are of little or no benefit in the automatic creation of a hypertext. However, it may be that this phenomenon is an artifact of the experimental procedure, and that such features might be better appreciated by users after a longer exposure to the system.
The inclusion of structural and referential links into the document base is a work in progress, as is the introduction of additional link types. User reaction to the latter is of great interest to us.
We intend to begin serious consideration of the use of some threshold, based on document similarity, for inclusion of semantic links into documents. This is another area which is of great interest to us.
In the longer term, we hope to repeat and extend this case study in order to determine whether LEIDIR is a more useful tool as a result of the modifications we have made, before going on to a more broadly based series of user evaluations.
Agosti, M., Crestani, F., and Melucci, M. On the use of information retrieval techniques for the automatic construction of hypertext. Information Processing and Management, 33(2):133-144, 1997.
Allan, J., Building hypertext using information retrieval. Information Processing and Management, Vol. 33, No. 2, 1997.
Baron, L., Tague-Sutcliffe, J., and Kinnucan, M.T. Labeled, typed links as cues when reading hypertext documents. Journal of the American Society for Information Science. 47(12):896-908, 1996.
Berners-Lee, T., Cailliau, R., Groff, J., and Pollermann, B. World Wide Web: The Information Universe. Electronic Networking: Research, Applications and Policy 1(2):74-82, 1992.
Dimitroff, A., and Wolfram, D. Searcher response in a hypertext-based bibliographic information retrieval system. Journal of the American Society for Information Science. 46(1):22-29, 1995.
Frisse, M. E. Searching for information in a hypertext medical handbook. Communications of the ACM, 31(7):880-886, 1988.
Harman, D., and Candela, G. Bringing natural language information retrieval out of the closet. SIGCHI Bulletin, 22(1):42-48, 1990.
Harman, D.K. (Editor) The Fourth Text REtrieval Conference (TREC-4). The National Institute of Standards and Technology Special Publication 500-236, 1996.
Raggett, D., HTML 3.2 Reference Specification, W3C Recommendation REC-html32, 14-Jan-1997, 1997.
Robertson, S.E., Walker, S., Jones, S., Hancock-Beaulieu, M.M. and Gatford, M., The Third Text REtrieval Conference (TREC-3). The National Institute of Standards and Technology Special Publication 500-225, 1995.
Salton, G., Singhal, A., Buckley, C., and Mitra, M. Automatic Text Decomposition Using Text Segments and Text Themes. Proceedings of the Seventh ACM Conference on Hypertext, 1996.
Thistlethwaite, P., Automatic construction and management of large open webs. Information Processing and Management, 33(2):161-173, 1997.
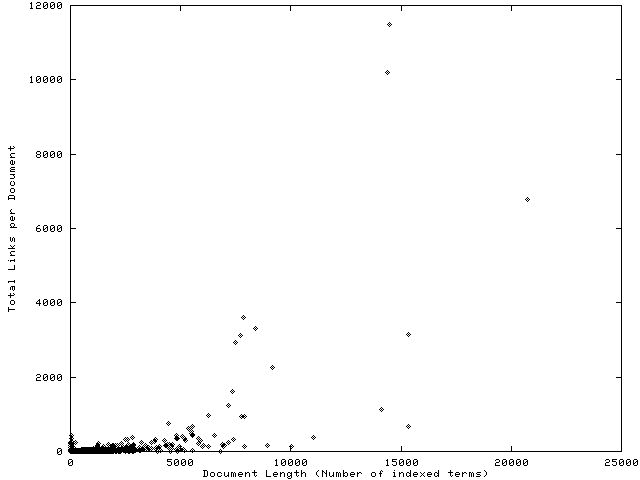
It turns out that this problem revolves around a small number of documents, the size of which is orders of magnitude greater than that of the majority. These were not broken up by our preprocessor module because of the parsing rule that each document must stand alone and make sense. Thus, the preprocessor has no length restrictions built into the documents it creates - it relies instead on each POMS Section to fall within a fairly narrow length distribution. Indeed, this is the case for Sections in all but two of the twelve Parts of the POMS.
We experienced some fairly serious effects as a result. First, long documents were ranked artificially highly in response to users' initial queries to the search engine. Second, and more damaging for our purposes here, the document web created by LEIDIR was distorted such that the link distribution, instead of being fairly uniform throughout the collection, was skewed towards the long documents. As a result, many regular documents contained links to one or more long documents, which usually were not closely related in terms of content. Finally, following a link to a long document almost invariably lead to a document with links only to other long documents, resulting in an information discovery "dead end".
It was the links to long documents which were felt to be inaccurate or unreliable by the study participants and, because such links were accompanied by a corresponding PSM, both the link and the PSM were perceived to be unreliable.
Figure 2 shows the total number of links to a document in the augmented POMS as a function of the document?s length. The figure is included here to provide a context for the discussion, and depicts clearly the powerful attraction of the very long documents to semantic hypertext links. In fact the eight longest documents (length > 10,000) attracted 33,944 links out of a total of 138,380, or 24.53% of all links. The total number of documents in the collection was 27,676, and they ranged in length from 4 to 20,750 terms, with a median length of 123 terms.
The disproportionate influence of very long documents on both the search results returned to the study participants and on the structure of the document web created by LEIDIR pointed up two shortcomings in the software which we had failed to account for.
First, the PRISE system does not perform any query processing, other
than stemming and the
removal of stop words. Thus the term weight for a given term effectively
increases by one for each occurrence of that term in the query. The term
weighting scheme usually associated with the PRISE system uses the familiar
"tf-IDF" type of formula:
Where:
n = the number of documents containing the term.
However, this effect mushrooms when whole documents are used as queries, and its size is indeterminate, though clearly dependent on the length of the query document simply because of the number of terms it contains. We feel that the presence of this effect in the document retrieval process had the greater part in promoting the disproportionately high ranking of very long documents, together with the associated side effects. However, the inclusion of this measure should not be discounted, as the terms in the query document provide a valuable source of information, just as is the case with short queries. The effect should be mitigated, though, by factoring in the length of the query document. This is an area for future research.
The second shortcoming of LEIDIR that came to light as a result of the
disproportionate influence of very long documents was insufficient document
length normalization. Though we feel this to be a secondary feature to
the presence of query term frequency in the weighting function, the size
difference between very long documents and the majority of documents is
too great to be accounted for by PRISE's length normalization function: