After 4 years on broadcast news, TRECVID 2007 will test its three fundamental tasks on new, related, but different video genres taken from a real archive - news magazine, science news, news reports, documentaries, educational programming, and archival video - to see how well the technologies apply to new sorts of data.
- shot boundary determination
- high-level feature extraction
- search (interactive, manually-assisted, and/or fully automatic)
A new pilot task with common evaluation will be added -
- rushes summarization
- in which systems will attempt to construct a minimally short video clip that includes the major objects and events of the video to be summarized. As with all the other tasks, system speed will be a fundamental measure, i.e., the time taken to generate the summary. If this task and its evaluation prove feasible and interesting to the community, we expect to focus more attention on it in the future.
The summarization of BBC rushes was run as a workshop at ACM MM '07 in Augsburg on 28. September with results reported at TRECVID 2007 in November. The schedule will be as indicated at the top of the Milestones section
For past participants, here are some changes to note:
- TRECVID 2007 will require a search/feature run treating the new video as if no automatic speech recognition (ASR) or machine translation (MT) for the languages of the videos (mostly Dutch) existed - as might occur in the case of video in other less well known languages. This will further emphasize the need to understand the visually-encoded information.
- An effort will be made to emphasize search for events (object+action) not easily captured in a single frame as opposed to searching for static objects.
- While mastershots will be defined as units of evaluation, keyframes or annotation of keyframes will not be provided by NIST. This will require groups to look afresh at how best to train their systems - tradeoffs between processing speed, effectiveness, amount of the video processed. As in the past, participants may want to team up to create training resources. The degree to which systems trained on broadcast news generalize with varying amounts of training data to a related but different genre will be a focus of TRECVID 2007.
2.1 Shot boundary detection:
Shots are fundamental units of video, useful for higher-level processing. The task is as follows: identify the shot boundaries with their location and type (cut or gradual) in the given video clip(s)
2.2 High-level feature extraction:
Various high-level semantic features, concepts such as "Indoor/Outdoor", "People", "Speech" etc., occur frequently in video databases. The proposed task will contribute to work on a benchmark for evaluating the effectiveness of detection methods for semantic concepts
The task is as follows: given the feature test collection, the common shot boundary reference for the feature extraction test collection, and the list of feature definitions (see below), participants will return for each feature the list of at most 2000 shots from the test collection, ranked according to the highest possibility of detecting the presence of the feature. Each feature is assumed to be binary, i.e., it is either present or absent in the given reference shot.
All feature detection submissions will be made available to all participants for use in the search task - unless the submitter explicitly asks NIST before submission not to do this.
Description of high-level features to be detected:
The descriptions are those used in the common annotation effort. They are meant for humans, e.g., assessors/annotators creating truth data and system developers attempting to automate feature detection. They are not meant to indicate how automatic detection should be achieved.
If the feature is true for some frame (sequence) within the shot, then it is true for the shot; and vice versa. This is a simplification adopted for the benefits it affords in pooling of results and approximating the basis for calculating recall.
NOTE: In the following, "contains x" is short for "contains x to a degree sufficient for x to be recognizable as x to a human" . This means among other things that unless explicitly stated, partial visibility or audibility may suffice.
Selection of high-level features to be detected:
In 2007 participants in the high-level feature
task must submit results for all of the following features (except those
3 that were dropped). NIST will then choose 10-20 of the features and evaluate
submissions for those. Use the following numbers when submitting the
features.
NOTE: NIST will instruct the assessors during the manual
evaluation of the feature task submissions as follows. The fact that a
segment contains video of physical objects representing the topic
target, such as photos, paintings, models, or toy versions of the
topic target, should NOT be grounds for judging the feature to be true
for the segment. Containing video of the target within video may be
grounds for doing so.
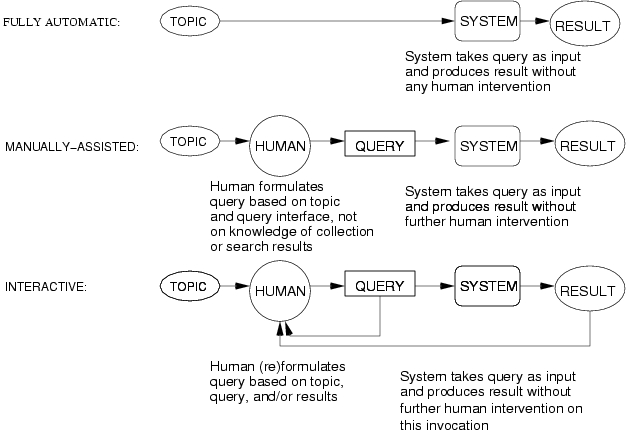
Search is high-level task which includes at least query-based
retrieval and browsing. The search task models that of an intelligence
analyst or analogous worker, who is looking for segments of video
containing persons, objects, events, locations, etc. of
interest. These persons, objects, etc. may be peripheral or accidental
to the original subject of the video. The task is as follows: given
the search test collection, a multimedia statement of information need
(topic), and the common shot boundary reference for the search test
collection, return a ranked list of at most 1000 common reference
shots from the test collection, which best satisfy the need. Please
note the following restrictions for this task:
2.3 Search:
2.4 Rushes summarization:
Rushes are the raw material (extra video, B-rolls footage) used to produce a video. 20 to 40 times as much material may be shot as actually becomes part of the finished product. Rushes usually have only natural sound. Actors are only sometimes present. So very little if any information is encoded in speech. Rushes contain many frames or sequences of frames that are highly repetitive, e.g., many takes of the same scene redone due to errors (e.g. an actor gets his lines wrong, a plane flies over, etc.), long segments in which the camera is fixed on a given scene or barely moving,etc. A significant part of the material might qualify as stock footage - reusable shots of people, objects, events, locations, etc. Rushes may share some characteristics with "ground reconnaissance" video.
The system task in rushes summarization will be, given a video from the rushes test collection, to automatically create an MPEG-1 summary clip less than or equal to a maximum duration (to be determined) that shows the main objects (animate and inanimate) and events in the rushes video to be summarized. The summary should minimize the number of frames used and present the information in ways that maximizes the usability of the summary and speed of objects/event recognition.
Such a summary could be returned with each video found by a video search engine much text search engines return short lists of keywords (in context) for each document found - to help the searcher decide whether to explore a given item further without viewing the whole item. It might be input to a larger system for filtering, exploring and managing rushes data.
Although in this pilot task we limit the notion of visual summary to a single clip that will be evaluated using simple play and pause controls, there is still room for creativity in generating the summary. Summaries need not be series of frames taken directly from the video to be summarized and presented in the same order. Summaries can contain picture-in-picture, split screens, and results of other techiniques for organizing the summary. Such approaches will raise interesting questions of usability. The summarization of BBC rushes was run as a workshop at ACM MM '07 in Augsburg on 28. September.
3. Video data:
A number of MPEG-1 datasets are available for use in TRECVID 2007. We describe them here and then indicate below which data will be used for development versus test for each task.
Sound and Vision
The Netherlands Institute for Sound and Vision has generously provided 400 hours of news magazine, science news, news reports, documentaries, educational programming, and archival video in MPEG-1 for use within TRECVID. We may have an additional 200 hours of non-commercial news and news magazine video in time to include. This is plenty for 2 or 3 years of work. TRECVID 2007 will use ~100 hours of this data in 2007:
- 6 hours for the shot boundary task
- 50 hours for development of search feature detection
- 50 hours for test of search and feature detection
BBB rushes
The BBC Archive has provided about 100 hours of unedited material in MPEG-1 from about five dramatic series. By the time the guidelines are complete (1 April) we will choose appropriate amounts for development and test of the rushes summarization task. Clips tend to have durations of 30 mins or less.
- ~50 clips for rushes summarization development
- ~50 clips for rushes summarization test
3.1 Development versus test data
The degree to which systems trained on broadcast news generalize with varying amounts of new training data to a related but different genre will be a focus of TRECVID 2007. Groups can train systems using the annotations and baselines developed for the TRECVID 2005 keyframes and available from the TRECVID/LSCOM/MediaMill websites (see TRECVID Past data page for links). Groups that participated in TRECVID 2005 or 2006 should already have copies of the keyframes. The 2005 keyframes are available for purchase from the LDC. The keyframes from 2003 are expected to be available from the LDC in April of 2007. Please check the LDC website for announcements.
From the workshop came the suggestion that only small amounts of new training data would be needed (a few hours' worth). The creation of such new annotations for some of the Sound and Vision data will be the responsibility of the participants. As in the past, participants may want to team up to create training resources.
3.2 Data distribution
Distribution of all development data and test data (including for the shot boundary task) will be by download from NIST's and any other password-protected mirror servers we are able to get set up.
3.3 Ancillary data associated with the development/test data
Collaborative annotation of Sound and Vision data
Georges Quénot and Stéphane Ayache of LIG (Laboratoire d'Informatique de Grenoble, formerly CLIPS-IMAG) have organized a collaborative annotation for TRECVID 2007 as this was organized for TRECVID 2003 and 2005. Participants in that effort are invited to take spart in experiments related to the use of active learning in the collaborative annotation process. Details about these experiment are available here.
Please cite the following paper with respect to the 2007 LIG collaborative annotation effort:
Stéphane Ayache and Georges Quénot, "TRECVID 2007 Collaborative Annotation using Active Learning,", TRECVID'2007 Workshop, Gaithersburg, MD, USA, November 5-6, 2007.
Output of an automatic speech recognition (ASR) system
The University of Twente has offered to provide the output of an automatic speech recognition system on the Sound and Vision data. We are not yet sure when this will be available.
Output of a machine translation system (X->English)
Christof Monz of Queen Mary, University London has contributed machine translation (Dutch to English) for the Sound and Vision video (ASR output or speech).
Common shot boundary reference:
Christian Petersohn at the Fraunhofer (Heinrich Hertz) Institute in Berlin has again provided the master shot reference. Please use the following reference in your papers:
C. Petersohn. "Fraunhofer HHI at TRECVID 2004: Shot Boundary Detection System", TREC Video Retrieval Evaluation Online Proceedings, TRECVID, 2004 URL: www-nlpir.nist.gov/projects/tvpubs/tvpapers04/fraunhofer.pdfPeter Wilkins and Kirk Zhang of the Dublin City University team have formatted the reference. The following paragraphs describe the method used in 2005/6 and repeated with the data for 2007.
To create the master list of shots, the video was segmented. The results of this pass are called subshots. Because the master shot reference is designed for use in manual assessment, a second pass over the segmentation was made to create the master shots of at least 2 seconds in length. These master shots are the ones to be used in submitting results for the feature and search tasks. In the second pass, starting at the beginning of each file, the subshots were aggregated, if necessary, until the currrent shot was at least 2 seconds in duration, at which point the aggregation began anew with the next subshot.
The emphasis in the common shot boundary reference will be on the shots, not the transitions. The shots are contiguous. There are no gaps between them. They do not overlap. The media time format is based on the Gregorian day time (ISO 8601) norm. Fractions are defined by counting pre-specified fractions of a second. In our case, the frame rate was 25fps. One fraction of a second is thus specified as "PT1001N30000F".
The video id has the format of "XXX" and shot id "shotXXX_YYY". The "XXX" is the sequence number of video onto which the video file name is mapped, this will be listed in the "collection.xml" file. The "YYY" is the sequence number of the shot.
The common shot boundary directory will contain these file(type)s:
- 1_devel_mp7.zip and 1_test_mp7.zip - bundles containing one file of shot information for each video file in the development and /test collections
- xxx.mp7.xml - master shot list for video with id "xxx" in collection.xml
- collection.xml - a list of the files in the collection
- time.elements - info on the meaning/format of the MPEG-7 MediaTimePoint and MediaDuration elements
NIST will not be supplying keyframes for the Sound and Vision video. This will require groups to look afresh at how best to train their systems - tradeoffs between processing speed, effectiveness, amount of the video processed.
3.5 Restrictions on use of development and test data
Each participating group is responsible for adhering to the letter and spirit of these rules, the intent of which is to make the TRECVID evaluation realistic, fair, and maximally informative about system effectiveness as opposed to other confounding effects on performance. Submissions, which in the judgment of the coordinators and NIST do not comply, will not be accepted.
Test data
The test data cannot be used for system development and system developers should have no knowledge of it until after they have submitted their results for evaluation to NIST. Depending on the size of the team and tasks undertaken, this may mean isolating certain team members from certain information or operations, freezing system development early, etc.
Participants may use donated feature extraction output from the test collection but incorporation of such features should be automatic so that system development is not affected by knowledge of the extracted features. Anyone doing searches must be isolated from knowledge of that output.
Participants cannot use the knowledge that the test collection comes from news video recorded during a known time period in the development of their systems. This would be unrealistic.
Development data
The development data is intended for the participants' use in developing their systems. It is up to the participants how the development data is used, e.g., divided into training and validation data, etc.
Other data sets created by LDC for earlier evaluations and derived from the same original videos as the test data cannot be used in developing systems for TRECVID 2007.
If participants use the output of an ASR/MT system, they must submit at least one run using the English ASR/MT provided by NIST. They are free to use the output of other ASR/MT systems in additional runs.
Participants may use other development resources not excluded in these guidelines. Such resources should be reported at the workshop. Note that use of other resources will change the submission's status with respect to system development type, which is described next.
- A - system trained only on common TRECVID development collection
data: annotations and truth data publicly available to all
participants. Such data include the TRECVID common annotations from
2003 and 2005, the LSCOM-lite and full LSCOM annotations, results of
NIST judging in earlier TRECVIDs, the MediaMill baseline from 2006,
any training data created for 2007 and shared with all participants -
that includes the results of the active learning annotation and those
provided by the MCG-ICT-CAS team for 2007.
Since by design we have multiple annotators for most of the common training data features but it is not at all clear how best to combine those sources of evidence, it seems advisable to allow groups using the common annotation to choose a subset and still qualify as using type A training. This may be equivalent to adding new negative judgments. However, no new positive judgments can be added.
- B - system trained only on common development collection but not on (just) common annotation of it
- C - system is not of type A or B
In 2007 there is special interest in how well systems trained on one sort of data generalize to another related, but different type of data with little or no new training data. The available training data contain some that is specific to the Sound and Vision video and some that is not. Therefore we are introducing three additional training categories:
- a - same as A but no training data (shared or private) specific to any Sound and Vision data has been used in the construction or running of the system.
- b - same as B but no training data (shared or private) specific to any Sound and Vision data has been used in the construction or running of the system.
- c - same as C but no training data (shared or private) specific to any Sound and Vision data has been used in the construction or running of the system.
We encourage groups to submit at least one pair of runs from their allowable total that helps the community understand how well systems trained on non-Sound-and-Vision data generalize to Sound-and-Vision data.
3.6 Data license agreements for active participants
In order to be eligible to receive the test data, you must have have
applied for participation in TRECVID, be acknowledged as an active
participant, have completed the relevant permission forms (from the
active participant's area) and faxed them (Attention: Lori Buckland)
to  in the US. Include a cover sheet with your fax that
identifies you, your organization, your email address, and the fact
that you are requesting the TRECVID 2007 BBC rushes and/or Sound
and Vision data. Ask only for the data required for the task(s) you
apply to participate in and intend to complete:
in the US. Include a cover sheet with your fax that
identifies you, your organization, your email address, and the fact
that you are requesting the TRECVID 2007 BBC rushes and/or Sound
and Vision data. Ask only for the data required for the task(s) you
apply to participate in and intend to complete:
- Shot boundaries -> Sound and Vision
- Search -> Sound and Vision
- Feature extraction -> Sound and Vision
- Rushes summarization -> BBC rushes
4. Topics:
4.1 Example types of video needs
I'm interested in video material containing:- a specific person
- one or more instances of a category of people
- a specific thing
- one or more instances of a category of things
- a specific event/activity
- one or more instances of a category of events/activities
- a specific location
- one or more instances of a category of locations
- combinations of the above
Topics may target commercials as well as news content.
4.2 Topics:
The topics, formatted multimedia statements of information need, will be developed by NIST who will control their distribution. The topics will express the need for video concerning people, things, events, locations, etc. and combinations of the former. Candidate topics (text only) will be created at NIST by examining a large subset of the test collection videos without reference to the audio, looking for candidate topic targets. Note: Following the VACE III goals, topics asking for video of events will be much more frequent this year - exploring the limits of one-keyframe-per-shot approaches for this kind of topic and encouraging exploration beyond those limits. Accepted topics will be enhanced with non-textual examples from the Web if possible and from the development data if need be. The goal is to create 24 topics.
* Note: The identification of any commercial product or trade name does not imply endorsement or recommendation by the National Institute of Standards and Technology
- Topics describe the information need. They are input to systems and guide to humans assessing relevance of system output
- Topics are multimedia objects - subject to the nature of the need and the questioner's choice of expression
- As realistic in intent and expression as possible
- Template for topic:
- Title
- Brief textual description of the information need (this text may contain references to the examples)
- Examples* of what is wanted:
- reference to video clip
- Optional brief textual clarification of the example's relation to the need
- reference to image
- Optional brief textual clarification of the example's relation to the need
- reference to audio
- Optional brief textual clarification of the example's relation to the need
5. Submissions and Evaluations:
Please note: Only submissions which are valid when checked against the supplied DTDs will be accepted. You must check your submission before submitting it. NIST reserves the right to reject any submission which does not parse correctly against the provided DTD(s). Various checkers exist, e.g., Xerces-J: java sax.SAXCount -v YourSubmision.xml..
The results of the evaluation will be made available to attendees at the TRECVID workshop and will be published in the final proceedings and/or on the TRECVID website within six months after the workshop. All submissions will likewise be available to interested researchers via the TRECVID website within six months of the workshop.
5.1 Shot boundary detection
- Participating groups may submit up to 10 runs. Please note required attributes to accommodate complexity information (total decode time (secs), total segmentation time(secs), and processor type) for each run are part of the submission DTD. All runs will be evaluated.
- Here is the DTD for the shot boundary detection results of one run, one for the enclosing shotBoundaryResults element and a small, partial example. Please place the output of each run in a separate file. You can tar/zip the (up to 10) run files together for submission. Remember that each run much test one variant of your system against all the test files. Please check your submission to see that it is well-formed
- Please send your submissions (up to 10 runs) in an email to over at nist.gov. Indicate somewhere (e.g., in the subject line) which group you are attached to so that we match you up with the active participant's database.
- Automatic comparison to human-annotated reference. Software for this comparison is available under Tools used by TRECVID from the main TRECVID page.
- Measures:
- All transitions: for each file, precision and recall for detection; for each run, the mean precision and recall per reference transition across all files
- Gradual transitions only: "frame-recall" and "frame precision" will be calculated for each detected gradual reference transition. Averages per detected gradual reference transition will be calculated for each file and for each submitted run. Details are available.
5.2 High-level feature extraction
Submissions
- Each group may submit up to 6 total runs. All runs must be prioritized and all will be evaluated.
- TRECVID 2007 will require a feature run treating the new video as if no automatic speech recognition (ASR) or machine translation (MT) for the languages of the videos (mostly Dutch) existed - as might occur in the case of video in other less well known languages.
- For each feature in a run, participants will return at most 2000.
- Here is a DTD for feature extraction results of one run, one for results from multiple runs, and a small example of what a site would send to NIST for evaluation. Please check your submission to see that it is well-formed
- Please send your submission in an email to NIST (overATnistDOTgov). Indicate somewhere (e.g., in the subject line) which group you are attached to so that we match you up with the active participant's database. Send all of your runs as one file or send each run as a file but please do not break up your submission any more than that.
- Each run must contain results for all features listed above
Evaluation
- The unit of testing and performance assessment will be the video shot as defined by the track's common shot boundary reference. The submitted ranked shot lists for the detection of each feature will be judged manually as follows. We will take all shots down to some fixed depth (in ranked order) from the submissions for a given feature - using some fixed number of runs from each group in priority sequence up to the median of the number of runs submitted by any group. We will then merge the resulting lists and create a list of unique shots. These will be judged manually down to some depth to be determined by NIST based on available assessor time and number of correct shots found. NIST will maxmize the number of shots judged within practical limits. We will then evaluate each submission to its full depth based on the results of assessing the merged subsets. This process will be repeated for each feature.
- If the feature is perceivable by the assessor for some frame (sequence) however short or long then, then we'll assess it as true; otherwise false. We'll rely on the complex thresholds built into the human perceptual systems. Search and feature extraction applications are likely - ultimately - to face the complex judgment of a human with whatever variability is inherent in that.
- Runs will be compared using precision and recall. Precision-recall curves will be used as well as average precision, which combines precision and recall. Use of inferred average precision is still under consideration, and, if adopted, the precision and recall measures will be based on a sample.
5.3 Search
Submissions
-
Each group may submit up to 6 total runs. All runs must be prioritized
and all will be evaluated.
Each interactive run will contain one result for each and every topic using the system variant for that run. Each result for a topic can come from only one searcher, but the same searcher does not need to be used for all topics in a run. If a site has more than one searcher's result for a given topic and system variant, it will be up to the site to determine which searcher's result is included in the submitted result. NIST will try to make provision for the evaluation of supplemental results, i.e., ones NOT chosen for the submission described above. Details on this will be available by the time the topics are released.
-
For manual and automatic systems, TRECVID 2007 will require:
- A run based only on the text from the (English and/or Dutch) ASR/MT output provided by NIST and on the text of the topics.
- A run using no text from ASR/MT output - as though we were dealing with video in a language for which ASR/MT was not available.
- For each topic in a run, participants will return the list of at most 1000 shots. Here is a DTD for search results of one run, one for results from multiple runs, and a small example of what a site would send to NIST for evaluation. Please check your submission to see that it is well-formed
- Please submit your system output following the instructions on the search submission webpage using the TRECVID 2007 active participants' password.
Evaluation
- The unit of testing and performance assessment will be the video shot as defined by the track's common shot boundary reference. The submitted ranked lists of shots found relevant to a given topic will be judged manually as follows. We will take all shots down to some fixed depth (in ranked order) from the submissions for a given topic - using some fixed number of runs from each group in priority sequence up to the median of the number of runs submitted by any group. We will then merge the resulting lists and create a list of unique shots. These will be judged manually to some depth to be determined by NIST based on available assessor time and number of correct shots found. NIST will maximize the number of shots judged within practical limits. We will then evaluate each submission to its full depth based on the results of assessing the merged subsets. This process will be repeated for each topic.
- Per-search measures:
- average precision (definition below)
- elapsed time (for all runs)
- Per-run measure:
-
mean average precision (MAP):
Non-interpolated average precision, corresponds to the area under an ideal (non-interpolated) recall/precision curve. To compute this average, a precision average for each topic is first calculated. This is done by computing the precision after every retrieved relevant shot and then averaging these precisions over the total number of retrieved relevant/correct shots in the collection for that topic/feature or the maximum allowed result set (whichever is smaller). Average precision favors highly ranked relevant documents. It allows comparison of different size result sets. Submitting the maximum number of items per result set can never lower the average precision for that submission. The topic averages are combined (averaged) across all topics in the appropriate set to create the non-interpolated mean average precision (MAP) for that set. (See the TREC-10 Proceedings appendix on common evaluation measures for more information.)
5.4 Rushes summarization
Submissions
-
Each participating group will submit to NIST one MPEG-1 summary clip
(same frame size and frame rate as the orginal videos: 352x288, 25fps)
for each of the test rushes videos along with the system time (in
seconds) needed to create the summary starting only with the video to
be summarized and the number of frames in the summary clip.
For practical reasons in planning the assessment we need an upper limit on the size of the summaries. Also, some very long summaries make no sense for a given use scenario. But you can imagine many scenarios to motivate various answers. One might involve passing the summary to downstream applications that support, clustering, filtering, sophisticated browsing for rushes exploration, management, reuse. Minimal emphasis on compression.
Assuming we want the summary to be directly usable by a human, then at least the summary should be usable by a professional, looking for reusable material, and willing to watch a summary longer than someone with more recreational goals.
Therefore we'll allow longer summaries than a recreational user would tolerate but score results so that systems that can meet a higher goal (much shorter summary) get rewarded - e.g., present mean-fraction-of-ground-truth-items-included versus duration-of-the-summary or calculate ratio.
Each submitted summary will have a duration which is at most 4% of the video to be summarized. That gives a mean maximum summary duration of 60 seconds with a range from 7 - 87 seconds). Remember 4% is not a goal - it is just an UPPER limit on size.
We currently plan to provide a simple webpage for groups to use in uploading their test summaries to NIST. This will process will probably take a file at a time, so tedious but better we hope than copying to DVD, packaging, sending, etc. More on the upload process in early May. In order to simplify the process we will require a naming convention for the summaries.
Please name your 42 test summaries *exactly* the same as the file containing the video being summarized *except* with ".sum" inserted before the ".mpg". For example, the summary of test file MS237650.mpg should be called MS237650.sum.mpg by every group. We will add a unique group prefix here.
Evaluation
-
At NIST, all the summary clips for a given video will be viewed using
mplayer on Linux in a window 125mm x 102mm @ 25 fps in a randomized
order by a single human judge. In a timed process, the judge will play
/ pause the video as needed to determine as quickly as possible which
of the objects and events listed in the ground truth for the video to
be summarized are present in the summary.
The judge will also be asked to assess the usability/quality of the summary. Included will be at least something like the following with 5 possible answers for each - where only the extremes are labeled: "Strongly agree" and "strongly disagree".
- It is easy to see and understand what is in this summary.
- This summary contains more video of the desired segments than was needed.
This process will be repeated for each test video. If possible we will have more than one human evaluate at least some of the videos.
- Per-summary measures:
- fraction of the ground truth objects/events found in the summary
- time (in seconds) needed to check summary against ground truth
- number of frames in the summary
- system time (in seconds) to generate the summary
- usability scores
- Per-system measures:
- Means of the above across all test videos (in relation to median/max for all systems
The output of two baseline systems will be provided by the Carnegie Mellon University team. One will be a uniform sample baseline within the 4% maximum. The other will likely be based on a sample within the 4% maximum from clusters built on the basis of a simple color histogram. More details later.
6. Milestones:
The following are the target dates for 2007.
This is the schedule for work on the BBC rushes summarization task
leading to the summarization workshop
to be held on Friday,
28. September at the ACM Multimedia '07 meeting in Augsburg, Germany:
1 Mar development data available for download
9 Mar sample ground truth for ~20 of 50 development videos available
15 Mar summarization guidelines complete
1 Apr test data available for download
11 May system output submitted to NIST for judging
1 Jun evaluation results distributed to participants
22 Jun papers (max 5 pages) due in ACM format
The organizers will provide in intro paper with information
about the data, task, groundtruthing, evaluation, measures, etc.
29 Jun acceptance notification
11 Jul camera-ready papers due via ACM process
28 Sep video summmarization workshop at ACM Multimedia '07, Augsburg, Germany.
- 2. Feb
- NIST sends out Call for Participation in TRECVID 2007
- 20. Feb
- Applications for participation in TRECVID 2007 due at NIST
- 1 Mar
- Final versions of TRECVID 2006 papers due at NIST
- 1. Apr
- Guidelines complete
- May
- Download of feature/search development data
- June
- Download of feature/search development data
- 18. June
- Download of feature/search test data
- 1. Jul
- Shot boundary test collection ready for download from NIST and mirror servers
- 3. Aug
- Search topics available from TRECVID website.
- 7. Aug
- Shot boundary detection submissions due at NIST for evaluation.
- 10. Aug
- Feature extraction tasks submissions due at NIST for evaluation.
Feature extraction donations due at NIST - 17. Aug
- Feature extraction donations available for active participants
- 17 Aug
- Results of shot boundary evaluations returned to participants
- 20. Aug - 5. Oct
- Search and feature assessment at NIST
- 14. Sep
- Results of feature extraction evaluations returned to participants
- 10. Sep
- Search task submissions due at NIST for evaluation
- 12. Oct
- Results of search evaluations returned to participants
- 15. Oct
- Speaker proposals due at NIST
- 22. Oct
- Notebook papers due at NIST
- 29. Oct
- TRECVID 2007 Workshop registration closes
- 1. Nov
- Copyright forms due back at NIST (see Notebook papers for instructions)
- 5,6 Nov
- TRECVID Workshop at NIST in Gaithersburg, MD(Registration, agenda, etc)
- 15. Dec
- Workshop papers publicly available (slides added as they arrive)
- 1. Mar 2008
- Final versions of TRECVID 2007 papers due at NIST
7. Outstanding 2007 guideline work items
Here is a list of work items that must be completed before the guidelines are considered to be final and the responsible parties.
- Need volunteer to create provide MT output (Dutch to English) for Sound and Vision data [NIST, coordinators, participants] ANSWER: Christof Monz of Queen Mary, University London has contributed machine translation (Dutch to English) for the Sound and Vision video (ASR output or speech).]
- Need to integrate collaborative search paradigm into guidelines[NIST, coordinators, interested parties (e.g., FxPal?)]
- Need to resolve availability of TRECVID 2005 keyframes[LDC, NIST] ANSWER:See summary evaluation section above.
- Need to decide how summaries will be submitted to NIST per video by each team[NIST] ANSWER: 1.
-
Need to decide on the maximum duration summaries[NIST, participants]
ANSWER: See
-
Need to decide on the summary usability questions[NIST]
ANSWER: See
- Need to decide on usage of inferred average precision[NIST, coordinators, participants] ANSWER: We plan to use it along with a simple approximation of precision and recall.
- Need to fix maximum number of feature and search runs permitted.[NIST] ANSWER: at most 6 total search runs group and at most 6 total feature extraction runs per group.
8. Results information
9. Contacts:
- Coordinators:
- and
- NIST contact:
- Email lists:
- Information and discussion for active workshop participants
- [email protected]
- archive open to active participants only
-
NIST will subscribe the contact listed in your application to
participate when we have received it. Additional members of active
participant teams will be subscribed by NIST if they send email to
indicating they want to be subscribed, the
email address to use, their name, and providing the TRECVID 2007
active participant's password. Groups may combine the information
for multiple team members in one email.
Once subscribed, you can post to this list by sending you thoughts as email to [email protected], where they will be sent out to everyone subscribed to the list, i.e., the other active participants.
- Information and discussion for active workshop participants working on the rushes summarization task
- [email protected]
- archive open to active participants only
-
NIST will subscribe the contact listed in your application to
participate when we have received it. Additional members of active
participant teams will be subscribed by NIST if they send email to
indicating they want to be subscribed, the
email address to use, their name, and providing the TRECVID 2007
active participant's password. Groups may combine the information
for multiple team members in one email.
Once subscribed, you can post to this list by sending you thoughts as email to [email protected], where they will be sent out to everyone subscribed to the list, i.e., the other active participants.
- General (annual) announcements about TRECVID (no discussion)
- [email protected]
- open archive
- If you would like to subscribe, logon using the logon to which you would like trecvid email to be reflected. Send email to [email protected] and ask her to subscribe you to trecvid. This list is used to notify interested parties about the call for participation and broader issues. Postings will be infrequent.
 Last
updated:
Last
updated: Date created: Monday, 24-Jan-06
For further information contact