 surveillance event detection content-based copy detection
surveillance event detection content-based copy detectionThe main goal of the TREC Video Retrieval Evaluation (TRECVID) is to promote progress in content-based analysis of and retrieval from digital video via open, metrics-based evaluation. TRECVID is a laboratory-style evaluation that attempts to model real world situations or significant component tasks involved in such situations.
In 2006 TRECVID completed the second two-year cycle devoted to automatic segmentation, indexing, and content-based retrieval of digital video - broadcast news in English, Arabic, and Chinese. It also completed two years of pilot studies on exploitation of unedited video (rushes). Some 70 research groups have been provided with the TRECVID 2005-2006 broadcast news video and many resources created by NIST and the TRECVID community are available for continued research on this data independent of TRECVID. See the "Past data" section of the TRECVID website for pointers.
In 2007 TRECVID began exploring new data (cultural, news magazine, documentary, and education programming) and an additional, new task - video rushes summarization. In 2008 that work will continue with the exception of the shot boundary detection task, which will be retired. In addition TRECVID plans to organize two new task evaluations.
TRECVID 2008 will test systems on the following tasks:
surveillance event detection content-based copy detectionFor past participants, here are some changes to note:
A number of datasets are available for use in TRECVID 2008. We describe them here and then indicate below which data will be used for development versus test for each task.
The copy detection task will use all 200 hours as test data; for development data under "MUSCLE-VCD-2007" data below.
C. Petersohn. "Fraunhofer HHI at TRECVID 2004: Shot Boundary Detection System", TREC Video Retrieval Evaluation Online Proceedings, TRECVID, 2004 URL: www-nlpir.nist.gov/projects/tvpubs/tvpapers04/fraunhofer.pdfCode developed by Peter Wilkins and Kirk Zhang at Dublin City University will be used to format the reference. The method used in 2005/6 and to be repeated with the data for 2008 is described here.
Marijn Huijbregts, Roeland Ordelman and Franciska de Jong, Annotation of Heterogeneous Multimedia Content Using Automatic Speech Recognition. in Proceedings of SAMT, December 5-7 2007, Genova, Italy
Further information about the data is available here.
In order to be eligible to receive the data, you must have have
applied for participation in TRECVID. Your application will be
acknowledged by NIST with information about how to obtain the
data. Then you will need to complete the relevant permission forms
(from the active participant's area) and fax them (Attention: Lori
Buckland) to  in the US. Include a cover sheet with your fax that
identifies you, your organization, your email address, and each kind
of data you are requesting. Alternatively you may email a
well-identified pdf of each signed form to
Please ask only for the test data (and optional development data)
required for the task(s) you apply to participate in and intend to
complete. One permission form will cover 2007 and 2008 BBC data. One
permission form will cover 2007 and 2008 Sound and Vision data.
in the US. Include a cover sheet with your fax that
identifies you, your organization, your email address, and each kind
of data you are requesting. Alternatively you may email a
well-identified pdf of each signed form to
Please ask only for the test data (and optional development data)
required for the task(s) you apply to participate in and intend to
complete. One permission form will cover 2007 and 2008 BBC data. One
permission form will cover 2007 and 2008 Sound and Vision data.
The guidelines for this task have been developed with input from the research community. Given 100 hours of surveillance video (50 hours training, 50 hours test) the task is to detect 3 or more events from the required event set and identify their occurrences temporally. Systems can make multiple passes before outputting a list of putative event observations (i.e., this is a retrospective detection task). Besides the retrospective task, participants may alternatively choose to do a "free style" analysis of the data. Further information about the tasks may be found at the following web sites:
Various high-level semantic features, concepts such as "Indoor/Outdoor", "People", "Speech" etc., occur frequently in video databases. The proposed task will contribute to work on a benchmark for evaluating the effectiveness of detection methods for semantic concepts
The task is as follows: given the feature test collection, the common shot boundary reference for the feature extraction test collection, and the list of feature definitions (see below), participants will return for each feature the list of at most 2000 shots from the test collection, ranked according to the highest possibility of detecting the presence of the feature. Each feature is assumed to be binary, i.e., it is either present or absent in the given reference shot.
All feature detection submissions will be made available to all participants for use in the search task - unless the submitter explicitly asks NIST before submission not to do this.
The descriptions are those used in the common annotation effort. They are meant for humans, e.g., assessors/annotators creating truth data and system developers attempting to automate feature detection. They are not meant to indicate how automatic detection should be achieved.
If the feature is true for some frame (sequence) within the shot, then it is true for the shot; and vice versa. This is a simplification adopted for the benefits it affords in pooling of results and approximating the basis for calculating recall.
NOTE: In the following, "contains x" is short for "contains x to a degree sufficient for x to be recognizable as x to a human" . This means among other things that unless explicitly stated, partial visibility or audibility may suffice.
NOTE: NIST will instruct the assessors during the manual evaluation of the feature task submissions as follows. The fact that a segment contains video of physical objects representing the topic target, such as photos, paintings, models, or toy versions of the topic target, should NOT be grounds for judging the feature to be true for the segment. Containing video of the target within video may be grounds for doing so.
In 2008, participants in the high-level feature
task must submit results for all 20 of the following features. NIST will
then choose 10-20 of the features and evaluate submissions for
those.
The features were drawn from the large LSCOM feature set so as to be
appropriate to the Sound and Vision data used in the feature and
search tasks. Some feature definitions were enhanced for greater
clarity, so it is important that the TRECVID feature descriptions be
used and not the LSCOM descriptions.
Search is high-level task which includes at least query-based
retrieval and browsing. The search task models that of an intelligence
analyst or analogous worker, who is looking for segments of video
containing persons, objects, events, locations, etc. of
interest. These persons, objects, etc. may be peripheral or accidental
to the original subject of the video. The task is as follows: given
the search test collection, a multimedia
statement of information need (topic), and the common shot
boundary reference for the search test collection, return a ranked
list of at most 1000 common reference shots from the test collection,
which best satisfy the need. Please note the following restrictions
for this task:
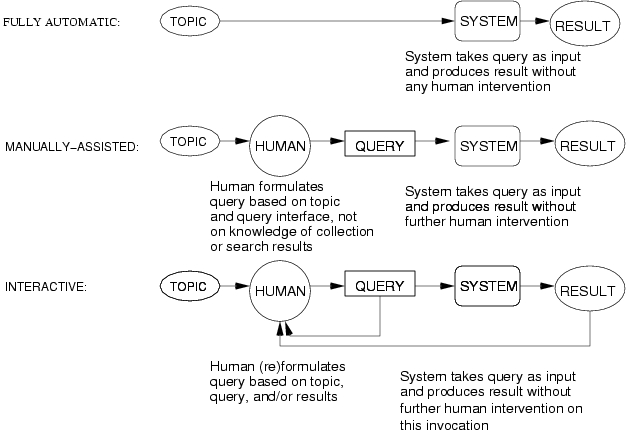
4.3 Search:
Rushes are the raw material (extra video, B-rolls footage) used to produce a video. 20 to 40 times as much material may be shot as actually becomes part of the finished product. Rushes usually have only natural sound. Actors are only sometimes present. So very little if any information is encoded in speech. Rushes contain many frames or sequences of frames that are highly repetitive, e.g., many takes of the same scene redone due to errors (e.g. an actor gets his lines wrong, a plane flies over, etc.), long segments in which the camera is fixed on a given scene or barely moving,etc. A significant part of the material might qualify as stock footage - reusable shots of people, objects, events, locations, etc. Rushes may share some characteristics with "ground reconnaissance" video.
The system task in rushes summarization will be, given a video from the rushes test collection, to automatically create an MPEG-1 summary clip less than or equal to a maximum duration (to be determined) that shows the main objects (animate and inanimate) and events in the rushes video to be summarized. The summary should minimize the number of frames used and present the information in ways that maximizes the usability of the summary and speed of objects/event recognition.
Such a summary could be returned with each video found by a video search engine much text search engines return short lists of keywords (in context) for each document found - to help the searcher decide whether to explore a given item further without viewing the whole item. It might be input to a larger system for filtering, exploring and managing rushes data.
Although in this task we limit the notion of visual summary to a single clip that will be evaluated using simple play and pause controls, there is still room for creativity in generating the summary. Summaries need not be series of frames taken directly from the video to be summarized and presented in the same order. Summaries can contain picture-in-picture, split screens, and results of other techniques for organizing the summary. Such approaches will raise interesting questions of usability.
The summarization of BBC rushes will be run as a workshop at the ACM Multimedia Conference in Vancouver, Canada during the last week of October 2008.
As used here, a copy is a segment of video derived from another video, usually by means of various transformations such as addition, deletion, modification (of aspect, color, contrast, encoding, ...), camcording, etc. Detecting copies is important for copyright control, business intelligence and advertisment tracking, law enforcement investigations, etc. Content-based copy detection offers an alternative to watermarking. The TRECVID copy detection task will be carried out in collaboration with members of the IMEDIA team at INRIA and will build on work demonstrated at CIVR 2007.
The required system task will be as follows: given a test collection of videos and a set of about 2000 queries (video-only segments), determine for each query the place, if any, that some part of the query occurs, with possible transformations, in the test collection. The set of possible transformations will be based to the extent possible on actually occurring transformations.
Each query will be constructed using tools developed by IMEDIA to include some randomization at various decision points in the construction of the query set. For each query, the tools will take a segment from the test collection, optionally transform it, embed it in some video segment which does not occur in the test collection, and then finally apply one or more transformations to the entire query segment. Some queries may contain no test segment; others may be composed entirely of the test segment. Video transformations to be used are documented in the general plan for query creation. and in the final video transformations document with examples..
Videos often contain audio. Sometimes the original audio is retained in the copied material, sometimes it is replaced by a new soundtrack. Nevertheless, audio is an important and strong feature for some application scenarios of video copy detection. Since detection of untransformed audio copies is relatively easy, and the primary interest of the TV community is in video analysis, it was decided to model the required CD task with video-only queries. However, since audio is of importance for practical applications, there will be two additional optional tasks: a task using transformed audio-only queries and one using transformed audio+video queries.
The audio-only queries will be generated along the same lines as the video-only queries: a set of 201 base audio-only queries is transformed by several techniques that are intended to be typical of those that would occur in real reuse scenarios: (1) bandwidth limitation (2) other coding-related distortion (e.g. subband quantization noise) (3) variable mixing with unrelated audio content. The transformed queries will be downloadable from NIST.
The audio+video queries will consist of the aligned versions of transformed audio and video queries, i.e, they will be various combinations of transformed audio and transformed video from a given base audio+video query. In this way sites can study the effectiveness of their systems for individual audio and video transformations and their combinations. These queries will not be downloadable. Rather, NIST will provide a list of how to construct each audio+video test query so that given the audio-only queries and the video-only queries, sites can use a tool such as ffmpeg to construct the audio+video queries.
Please watch the schedule for information soon about the sequence of query releases and results due dates.
Please note: Only submissions which are valid when checked against the supplied DTDs will be accepted. You must check your submission before submitting it. NIST reserves the right to reject any submission which does not parse correctly against the provided DTD(s). Various checkers exist, e.g., Xerces-J: java sax.SAXCount -v YourSubmision.xml.
The results of the evaluation will be made available to attendees at the TRECVID workshop and will be published in the final proceedings and/or on the TRECVID website within six months after the workshop. All submissions will likewise be available to interested researchers via the TRECVID website within six months of the workshop.
The guidelines for submission are currently being developed.
Further information on submissions may be found here.
Output from systems will first be aligned to ground truth annotations, then scored for misses / false alarms. Since error is a tradeoff between probability of miss vs. rate of false alarms, this task will use the Normalized Detection Cost Rate (NDCR) measure for evaluating system performance. NDCR is a weighted linear combination of the system's Missed Detection Probability and False Alarm Rate (measured per unit time).
Further information about the evaluation measures may be found here.
Each interactive run will contain one result for each and every topic using the system variant for that run. Each result for a topic can come from only one searcher, but the same searcher does not need to be used for all topics in a run. If a site has more than one searcher's result for a given topic and system variant, it will be up to the site to determine which searcher's result is included in the submitted result. NIST will try to make provision for the evaluation of supplemental results, i.e., ones NOT chosen for the submission described above. Details on this will be available by the time the topics are released.
For practical reasons in planning the assessment we need an upper limit on the size of the summaries. Also, some very long summaries make no sense for a given use scenario. But you can imagine many scenarios to motivate various answers. One might involve passing the summary to downstream applications that support, clustering, filtering, sophisticated browsing for rushes exploration, management, reuse. Minimal emphasis on compression.
Assuming we want the summary to be directly usable by a human, then at least the summary should be usable by a professional, looking for reusable material, and willing to watch a summary longer than someone with more recreational goals.
Therefore we'll allow longer summaries than a recreational user would tolerate but score results so that systems that can meet a higher goal (much shorter summary) get rewarded - e.g., present mean-fraction-of-ground-truth-items-included versus duration-of-the-summary or calculate ratio.
Each submitted summary will have a duration which is at most 2% of the video to be summarized. Remember 2% is not a goal - it is just an UPPER limit on size.
The primary method for submitting summaries to NIST will be as follows. Each group will create one file containing a list of URLs - one URL per line for each summary they are submitting. If the group is submitting only one run then the URL file will contain 40 URL lines; if two runs, then it will contain 80 URL lines.
The first two lines of the URL file will contain the userid (on line 1) and the password (on line 2) to be used to access the summaries. We expect the summaries to be in a protected (non-spidered) directory. The scheme in each URL can be "http" or "ftp". For example:
http://HOST/PATH/TO/SUMMARIES/1.MS237650.sum.mpg
Please name your test summaries *exactly* the same as the file containing the video being summarized *except* with the priority ( "1" or "2") and ".sum" inserted before the ".mpg". For example, the priority 1 summary of test file MS237650.mpg should be called 1.MS237650.sum.mpg by every group. NIST will add a unique group prefix here.
NIST will provide webpage each group can use to identify itself, provide a contact email address, and type in the name of their URL file for upload to NIST. Once the URL file has been uploaded, it will be checked for simple errors and a message sent to the browser. After that NIST will proceed to use the URLs to upload each summary. An email will be sent to the submitting person as each summary is uploaded. This will allow the submitter to see the progress and provide detailed information about which, if any, uploads failed.
Although a little more complicated than last year, we hope the method will be less labor-intensive than last year's method which required each summary's name to be entered individually and uploaded before going on to the next.
If you cannot make use of the primary submission method described above you must notify NIST immediately so we can arrange for you to use last year's method for submission. In which case, you will need to leave more time for submission.
In the body of an email with your short team name in the subject, please send to the timing information for your summaries. At the top of the file place the following information:
Operating system CPU type MemoryThen include a line for each summary with the elapsed time in seconds to create that summary. For example:Short_team_ID Time(s) Priority Video_being_summarized Brno 469.36 1 MRS035126.mpg Brno 443.74 1 MRS042538.mpg Brno 573.94 1 MRS043405.mpg Brno 665.83 1 MRS044497.mpg Brno 470.94 1 MRS044499.mpg Brno 869.20 1 MRS044725.mpg Brno 369.14 1 MRS044728.mpg ...
The judge will also be asked to assess the usability/quality of the summary. Included will be at least something like the following with 5 possible answers for each - where only the extremes are labeled: "Strongly agree" and "strongly disagree".
This process will be repeated for each test video. If possible we will have more than one human evaluate at least some of the videos.
Carnegie Mellon University will again provide a simple baseline system to produce summaries within the 2% maximum. The baseline algorithm simply presents the entire video at 50x normal speed.
The following are the target dates for 2008.
The schedule for the surveillance event detection task listed at the end of this document .
Just below is the proposed schedule for work on the BBC rushes
summarization task that will be held as a workshop at the ACM
Multimedia Conference in Vancouver, Canada during the last week of
October 2008. Results will be summarized at the TRECVID workshop in
November. Papers reporting participants' summarization that are not
included in the ACM Multimedia Worhshop proceedings should be
submitted for inclusioni in the TRECVID workshop notebook.
1 Apr test data available for download
5 May system output submitted to NIST for judging at DCU
1 Jun evaluation results distributed to participants
28 Jun papers (max 5 pages) due in ACM format
The organizers will provide an intro paper with information
about the data, task, groundtruthing, evaluation, measures, etc.
15 Jul acceptance notification
1 Aug camera-ready papers due via ACM process
31 Oct video summarization workshop at ACM Multimedia '08, Vancouver, BC, Canada
Here is a list of work items that must be completed before the guidelines are considered to be final..
Once subscribed, you can post to this list by sending you thoughts as email to [email protected], where they will be sent out to everyone subscribed to the list, i.e., the other active participants.
 Last
updated:
Last
updated: