Deep Video Understanding (DVU)
Task Coordinators: Keith Curtis, George Awad, and Afzal Godil
Deep video understanding is a difficult task which requires computer vision systems to develop a deep analysis and understanding of the relationships between different entities in video, to use known information to reason about other, more hidden information, and to populate a knowledge graph (KG) with all acquired information. The aim of the proposed task is to push the limits of multimedia analysis techniques to address analyzing long duration videos holistically and extract useful knowledge to utilize it in solving different kind of queries. The knowledge in the target queries includes both visual and non-visual elements. Participating systems should take into consideration all available modalities (speech, image/video, and in some cases text).
As movies provide an excellent testbed to provide the needed data because they can simulate the real world (people, relationships, locations, actions and interactions, motivations, intentions, etc) the DVU task is exercising it's challenge on the movie domain. As videos and multimedia data are getting more and more popular and usable by users in different domains, the research, approaches and techniques we aim to be applied in this task will be very relevant in the coming years and near future.
New this year is a robustness subtask which will ask teams to submit results against the same testing dataset but with added noise to the visual and audio channels. The goal is to measure how much systems are robust against real-world perturbations.
System Task
The task for participating researchers will be: given a whole original movie (e.g 1.5 - 2hrs long), image snapshots of main entities (persons, locations, and concepts) per movie, and ontology of relationships, interactions, locations, and sentiments used to annotate each movie at global movie-level (relationships between entities) as well as on fine-grained scene-level (scene sentiment, interactions between characters, and locations of scenes), systems are expected to generate a knowledge-base of the main actors and their relations (such as family, work, social, etc) over the whole movie, and of interactions between them over the scene level. This representation is expected to support systems in answering a set of queries on the movie-level and/or scene-level (see below details about query types) per movie. The task will support two tracks (subtasks) where teams can join one or both tracks. Movie track where participants are asked queries on the whole movie level, and Scene track where Queries are targeted towards specific movie scenes.Deep Video Understanding Robustness SubTask
Building robust multimodal systems are critical for achieving deployment of these systems for real-world applications. Despite their significance, little attention has been paid to detecting and improving the robustness of multimodal systems.The Deep Video Understanding subtask challenge is focused on developing technology that reduces the gap in performance between training sets and real-world testing cases. The goal of this challenge is to promote algorithm development that can handle the various types of perturbations and corruptions observed in real-world multimodal data.
The robustness experiments will be evaluated based on the system’s performance on the test dataset with natural corruptions and perturbations. The natural perturbations will include spatial corruptions, temporal corruptions, spatio-temporal corruptions, different types of noise, and compression artifacts. We will create the dataset synthetically with a computer program with different levels of corruptions and perturbations to both the audio and video parts.
Robustness Dataset (preliminary info)
- The robustness dataset will use the same main task testing dataset.
- Movie dataset will include two levels of audio only perturbations.
- Movie dataset will include two levels of video only perturbations.
- Teams should handle and treat each testing dataset (the main dataset and the robustness dataset) independently. This implies processing them separately without using any knowledge about one of them to affect results of the other dataset.
Data Resources
The Development Dataset
The dataset will consist of two types of movie data with total of 19 movies (~ 23 hr) to support the Deep Video Understanding (DVU) task:A set of 14 Creative Common (CC) movies (total duration of 17.5 hr) previously utilized between 2020 and 2022 ACM Multimedia DVU Grand Challenges including their movie-level and scene-level annotations. The movies have been collected from public websites such as Vimeo and the Internet Archive. In total, the 14 movies from diverse genres consist of 621 scenes, 1572 entities, 650 relationships, and 2491 interactions.
The second is 5 licensed movies from KinolorberEdu platform and have been used as testing data in 2022.
The development dataset can be accessed from this URL. Please consult the documentation folder readme files for more information on the contents of the dataset. Note that the 5 KinolorberEdu movies need to be downloaded separately after signing the data agreement form (See the data use agreements).-
The 2022 queries and ground truth for both the TRECVID task as well as the ACM MM Grand Challenge can be found here:
2022 TRECVID DVU Queries and Ground Truth
2022 ACMMM Grand Challenge DVU Queries and Ground Truth
The Testing Dataset
A set of 4 to 6 new movies (total duration of ~ 6 hrs) will be distributed to participating teams. The movies have been licensed by NIST from the Kinolorberedu platform. All task participants will be able to download the movies after signing a data agreement. Please refer to the TRECVID 2023 schedule for availability of testing data, queries, and run submissions.
Subtasks and Query types
Query types will be comprised of four groups of queries. Teams can submit to either the Movie-level queries only, the scene-level queries only, or both the movie and scene queries.
Movie-level Track
- Query 1 - Fill in the Graph Space
Fill in spaces in the Knowledge Graph (KG). Given the listed relationships, events or actions for certain nodes, where some nodes are replaced by variables X, Y, etc., solve for X, Y etc. Example of The Simpsons: X Married To Marge. X Friend Of Lenny. Y Volunteers at Church. Y Neighbor Of X. Solution for X and Y in that case would be: X = Homer, Y = Ned Flanders. - Query 2 - Question Answering (QA)
This query type represents questions on the resulting knowledge base of the movies in the testing dataset. For example, we may ask 'How many children does Person A have?', in which case participating researchers should count the 'Parent Of' relationships Person A has in the Knowledge Graph. These queries also contain human-generated questions. These are open domain questions which are not limited to the ontology. This query type will take a multiple choice questions format.
The below is a sample of a movie-level QA query. Image snapshots of the entities mentioned in the query (person and locations) will be Given with the testing dataset and queries.
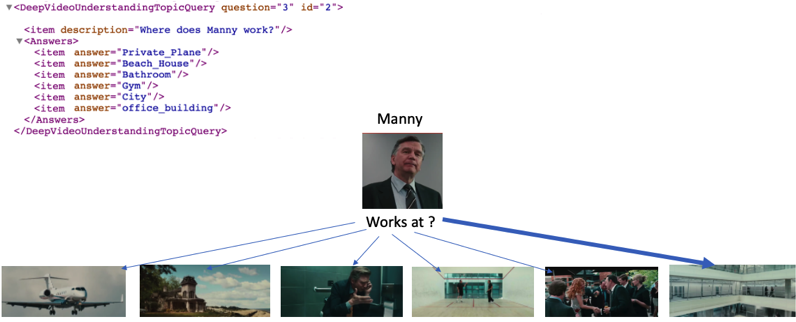
- Query 1 - Fill in the Graph Space
Scene-level Track
- Query 1 - Find the Unique Scene
Given a full, inclusive list of interactions, unique to a specific scene in the movie, teams should find which scene this is. - Query 2 & 3 - Find Next or Previous Interaction
Given a specific scene and a specific interaction between person X and person Y, participants will be asked to return either the previous interaction or the next interaction, in either direction, between person X and person Y. This can be specifically the next or previous interaction within the same scene, or over the entire movie. This query type will take a multiple choice questions format. - Query 4 - Match Scene to Text Description
Given a list of natural language descriptions of scenes and a list of scene numbers, match the descriptions with the scene number. - Query 5 - Scene Sentiment Classification
Given a specific movie scene and a set of possible sentiments, classify the correct sentiment label for each given scene.
The below is a sample of a scene-level find an interaction query. Image snapshots of the entities mentioned in the query (two persons) will be Given with the testing dataset and queries, while the interactions are included in the ontology distributed with the task.

- Query 1 - Find the Unique Scene
Metrics
- Movie-level : Fill in the Graph Space
Results will be treated as ranked list of result items per each unknown variable and the Reciprocal Rank score will be calculated per unknown variable and Mean Reciprocal Rank (MRR) per query. - Movie-level : Question Answering
Scores for this query will be calculated by the number of Correct Answers / number of Total Questions. - Scene-level : Find the Unique Scene
Results will be treated as ranked list of result items per each unknown variable and the Reciprocal Rank score will be calculated per unknown variable and Mean Reciprocal Rank (MRR) per query. - Scene-level : Find Next or Previous Interaction
Scores for this query will be calculated by the number of Correct Answers / number of Total Questions. - Scene-level : Match Scene to Text Description
Scores for this query will be calculated by the number of Correct Answers / number of Total Questions. - Scene-level : Scene Sentiment Classification
Scores for this query will be calculated by the number of Correct Answers / number of Total Questions. - The Robustness subtask will be evaluated using the same metrics as the main task, as well as derived measure as average-case performance over a set of corruptions
Run Submission Types & Conditions
- Teams can submit to the main and/or the robustness subtask in either the Movie-level queries only, the scene-level queries only, or both the movie and scene queries.
- For movie-level queries, teams can choose to submit results to either or both groups of:
- Group 1 - Query 1 (Fill in the Graph Space)
- Group 2 - Query 2 (Question Answering)
- For scene-level queries, teams can choose to submit results to either or both groups of:
- Group 1 - Queries 1, 2 & 3 (all related to interactions between characters)
- Group 2 - Queries 4 & 5 (matching of scenes and their descriptions in text, and sentiment classification)
- Teams should label their run file names to indicate if the run belongs to "main" OR "robustness" task.
Run submission format
Each participating team can submit up to 4 runs per track (movie or scene) in each of the two tasks (main and robustness). Each run should contain results for all queries within the answered query group in the testing dataset (see run submission types for movie and scene query groups). Please see the provided DTD files for run formats of both movie-level and scene-level results.Also, a small xml example for movie-level run and scene-level run. The below are sample queries and responses of movie and scene level queries:
- Movie-level fill in the graph sample query:
- Movie-level fill in the graph Sample response:
- Movie-level question answering sample query:
- Movie-level question answering Sample response:
- Scene-level find unique scene sample query:
- Scene-level find unique scene Sample response:
- Scene-level next interaction sample query:
- Scene-level next interaction Sample response:
- Scene-level previous interaction sample query:
- Scene-level previous interaction Sample response:
- Scene-level Match Scene to Text Description sample query:
- Scene-level Match Scene to Text Description Sample response:
- Scene-level Scene Sentiment Classification sample query:
- Scene-level Scene Sentiment Classification Sample response:


News magazine, science news, news reports, documentaries, educational programming, and archival video

TV Episodes

Airport Security Cameras & Activity Detection

Video collections from News, Sound & Vision, Internet Archive,
Social Media, BBC Eastenders