|
TIPSTER Text Program A multi-agency, multi-contractor program | |||||||||||||||||||||||||||
|
TABLE OF CONTENTS Introduction TIPSTER Overview TIPSTER Technology Overview TIPSTER Related Research Phase III Overview TIPSTER Calendar Reinvention Laboratory Project What's New Conceptual Papers Generic Information Retrieval Generic Text Extraction Summarization Concepts 12 Month Workshop Notes Conferences Text Retrieval Conference TREC-7 Participation Call Multilingual Entity Task Summarization Evaluation More Information Other Related Projects Document Down Loading Request for Change (RFC) Glossary of Terms TIPSTER Contacts TIPSTER Source Information Return to Retrieval Group home page Return to IAD home page Last updated: Date created: Monday, 31-Jul-00 |
Notes from TIPSTER 12 month Workshop The following material is from the 12 month TIPSTER Workshop. Various study groups
composed of attendees examined several areas related to TIPSTER and presented their
conclusions to all attendees at the end of the workshop. These Report Outs are summarized
below for the following areas: Document Detection Report
Info Seek, MatchPlus, Inquiry, Inktomi (Berkeley) TREC Collection provides ground truth- that's the big contribution from TIPSTER Does Government (IC) have unique needs? Yes.
So, which should industry address?
Maybe --
No --
Areas that need to be addressed in future:
What are some resources which researchers could use/need?
Should we develop five-primary models? (are users too unpredictable?) We need to develop other means of evaluating (in addition to precision and recall). No breakthrough if we continue to evaluate with only TREC. How to change TREC to be more real world. Apply for "Innovative Funds" Types of analyst; how they work Some research should be using intelligence analysts. Currently it takes analysts too long to search and fix. Is new "Thinking Tool" category in tech strategy? Commercial world is not there. Interface matters and can be studied. Need to identify types of tasks which users do. Ideally, have various kinds of modules to hook together in various ways. Internet saturated by advertising. Document Detection's Future
Understand Application Areas
3. Correlation among Event Types (Fusion) Resources used in Document Detection
Extraction Report Research Areas
Critical Areas for Research Push
Evaluation Is Driving Technology
Government and Private Sector Very Similar Needs
Ways to get evaluation to drive the research/technology
Depending on what you're extracting (domain) the techniques need to change Multi-Lingual Report No one addressing cross-lingual (industry seems more interested in one-to-one Perhaps folks don't believe in cross-lingual (since MT hasn't worked) At MT Summit - all wanted MT to "their" language There is a need for training data It was suggested we ask contractors to work up documents and send back Could Lexis-Nexis customers work up documents? Critical gap for Multi-Lingual is lack of training data GVE Languages - about 12 are really important for CIA and NSA Spend money on GVE There is limited support for other than core languages Ability to "ramp up" in "core language" would be really advantageous There are 250 languages in which the Government desires capability Is MUTT system used for MVC Need a Text Widget which supports languages Need auto and semi-auto bilingual dictionaries and OCR Multi-lingual:
Cross-Lingual:
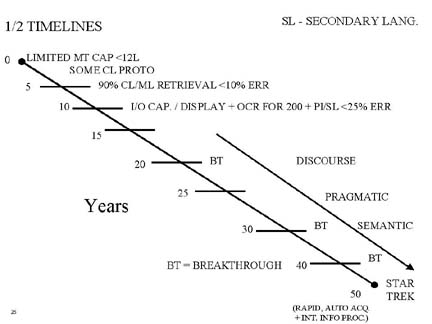
1. Current State of the Art
(b) Cross-language
2. Timelines
3. The Impact of this Technology? Quality?
4. Types of Infrastructure Needed? 5. Commercial World Benefits? 6. Government Special Needs
Summarization Report Good attendance (75 folks) We should do fun stuff first to generate interest How should we get output from system Sources of info for summary
Users want different things from summary Lexis-Nexis - need specific, unique summaries for certain users
Types of systems (components which have to share to make this work) Swap/Share modules What have we done? Good progress 2 years ago - not much work Now basic summary is easier In 3 years user profiles should be available In 4 years lexical/semantic Description of dry run for Summarization Dry run pointed out what can be controlled Some cross-doc evaluation
2. Legal specialist - Lexis-Nexis
3. Financial analysts - numerical
4. IR/VRT engine 1. Maximum marginal relevance engine 2. Coreference engine 3. NP Level Summarization 4. Topic ID 5 Term expansion 6. User profiling 7. Script/frame/pattern Status of Technology
T:
T + 3 years:
T+6 years (?):
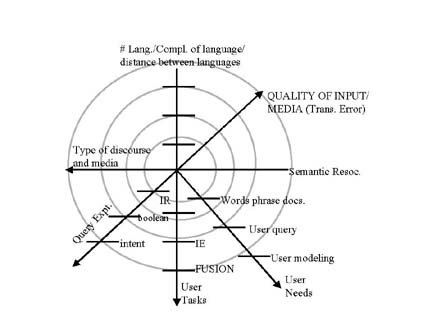
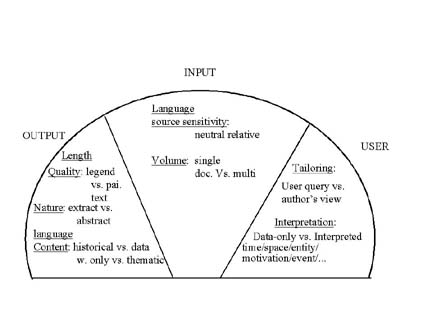
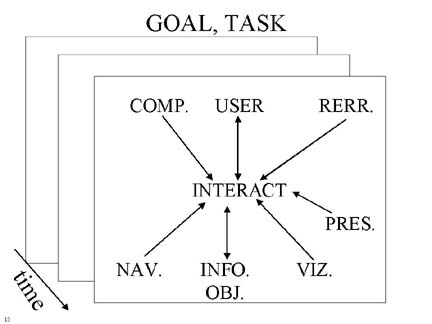
Human/Computer Interface Report
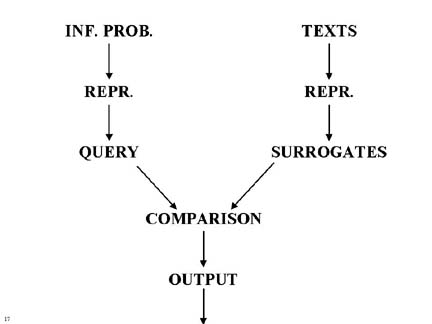
Comparison
Representation
Presentation
Visualization
Navigation
User
Interaction
Information Objects
People involved in information creation and use
Future.
|